
Distributed Representations of Tuples for Entity Resolution
Muhammad Ebraheem, Saravanan Thirumuruganathan, Shafiq Joty, Mourad Ouzzani, and Nan Tang
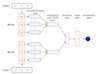
Despite the efforts in 70+ years in all aspects of Entity res- olution (ER), there is still a high demand for democratizing ER – by reducing the heavy human involvement in label- ing data, performing feature engineering, tuning parameters, and defining blocking functions. With the recent advances in deep learning, in particular distributed representations of words (a.k.a. word embeddings), we present a novel ER sys- tem, called DeepER, that achieves good accuracy, high effi- ciency, as well as ease-of-use (i.e., much less human efforts). We use sophisticated composition methods, namely uni- and bi-directional recurrent neural networks (RNNs) with long short term memory (LSTM) hidden units, to convert each tuple to a distributed representation (i.e., a vector), which can in turn be used to effectively capture similarities be- tween tuples. We consider both the case where pre-trained word embeddings are available as well the case where they are not; we present ways to learn and tune the distributed representations that are customized for a specific ER task under different scenarios. We propose a locality sensitive hashing (LSH) based blocking approach that takes all at- tributes of a tuple into consideration and produces much smaller blocks, compared with traditional methods that con- sider only a few attributes. We evaluate our algorithms on multiple datasets (including benchmarks, biomedical data, as well as multi-lingual data) and the extensive experimental results show that DeepER outperforms existing solutions.
Distributed Representations of Tuples for Entity Resolution
Muhammad Ebraheem, Saravanan Thirumuruganathan, Shafiq Joty, Mourad Ouzzani, and Nan Tang. In The Forty-fourth International Conference on Very Large Data Bases (VLDB-2018) , pages 1454 - 1467, 2018.
PDF Abstract BibTex Slides
Muhammad Ebraheem, Saravanan Thirumuruganathan, Shafiq Joty, Mourad Ouzzani, and Nan Tang. In The Forty-fourth International Conference on Very Large Data Bases (VLDB-2018) , pages 1454 - 1467, 2018.
PDF Abstract BibTex Slides