Publications
 Google scholar listing
Google scholar listing Selected Preprints (not peer reviewed)
2025

SFR-DeepResearch: Towards Effective Reinforcement Learning for Autonomously Reasoning Single Agents
Xuan-Phi Nguyen, Shrey Pandit, Revanth Gangi, Austin Xu, Silvio Savarese, Caiming Xiong, and Shafiq Joty. 2025.
PDF BibTex Slides
Xuan-Phi Nguyen, Shrey Pandit, Revanth Gangi, Austin Xu, Silvio Savarese, Caiming Xiong, and Shafiq Joty. 2025.
PDF BibTex Slides
Published papers (journals, confereces, workshops)
All papers have been subject to peer review unless indicated otherwise. * indicates equal contributions.2026
Least-Loaded Expert Parallelism: Load Balancing An Imbalanced Mixture-of-Experts
Xuan-Phi Nguyen, Shrey Pandit, Austin Xu, Caiming Xiong, and Shafiq Joty. In International Conference on Machine Learning (ICML-26) 2026.
PDF BibTex Slides
Xuan-Phi Nguyen, Shrey Pandit, Austin Xu, Caiming Xiong, and Shafiq Joty. In International Conference on Machine Learning (ICML-26) 2026.
PDF BibTex Slides

MAS-Orchestra: Understanding and Improving Multi-Agent Reasoning Through Holistic Orchestration and Controlled Benchmarks
Zixuan Ke, Yifei Ming, Austin Xu, Ryan Chin, Xuan-Phi Nguyen, Prathyusha Jwalapuram, Jiayu Wang, Semih Yavuz, Caiming Xiong, and Shafiq Joty. In International Conference on Machine Learning (ICML-26) 2026.
PDF BibTex Slides
Zixuan Ke, Yifei Ming, Austin Xu, Ryan Chin, Xuan-Phi Nguyen, Prathyusha Jwalapuram, Jiayu Wang, Semih Yavuz, Caiming Xiong, and Shafiq Joty. In International Conference on Machine Learning (ICML-26) 2026.
PDF BibTex Slides
MAS-ProVe: Understanding the Process Verification of Multi-Agent Systems
Vishal Venkataramani, Haizhou Shi, Zixuan Ke, Austin Xu, Xiaoxiao He, Yingbo Zhou, Semih Yavuz, Hao Wang, and Shafiq Joty. In International Conference on Machine Learning (ICML-26) 2026.
PDF BibTex Slides
Vishal Venkataramani, Haizhou Shi, Zixuan Ke, Austin Xu, Xiaoxiao He, Yingbo Zhou, Semih Yavuz, Hao Wang, and Shafiq Joty. In International Conference on Machine Learning (ICML-26) 2026.
PDF BibTex Slides
Hard2Verify: A Step-Level Verification Benchmark for Open-Ended Frontier Math
Shrey Pandit, Austin Xu, Xuan-Phi Nguyen, Yifei Ming, Caiming Xiong, and Shafiq Joty. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL-26) 2026.
PDF BibTex Slides
Shrey Pandit, Austin Xu, Xuan-Phi Nguyen, Yifei Ming, Caiming Xiong, and Shafiq Joty. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL-26) 2026.
PDF BibTex Slides

J4R: Learning to Judge with Equivalent Initial State Group Relative Policy Optimization
Austin Xu, Yilun Zhou, Xuan-Phi Nguyen, Caiming Xiong, and Shafiq Joty. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL-26) 2026.
PDF BibTex Slides
Austin Xu, Yilun Zhou, Xuan-Phi Nguyen, Caiming Xiong, and Shafiq Joty. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL-26) 2026.
PDF BibTex Slides

Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction
Zhenmei Shi, Yifei Ming, Xuan-Phi Nguyen, Yingyu Liang, and Shafiq Joty. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL-26 Findings) 2026.
PDF BibTex Slides
Zhenmei Shi, Yifei Ming, Xuan-Phi Nguyen, Yingyu Liang, and Shafiq Joty. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL-26 Findings) 2026.
PDF BibTex Slides

Lost in Translation: Do LVLM Judges Generalize Across Languages?
Md Tahmid, Mohammed Saidul, Mir Tafseer, Md Amran, Mizanur Rahman, Shafiq Joty, Enamul Hoque, and Jimmy Huang. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL-26 Findings) 2026.
BibTex Slides
Md Tahmid, Mohammed Saidul, Mir Tafseer, Md Amran, Mizanur Rahman, Shafiq Joty, Enamul Hoque, and Jimmy Huang. In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL-26 Findings) 2026.
BibTex Slides

Foundational Automatic Evaluators: Scaling Multi-Task Generative Evaluator Training for Reasoning-Centric Domains
Austin Xu, Xuan-Phi Nguyen, Yilun Zhou, Chien-Sheng Wu, Caiming Xiong, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides
Austin Xu, Xuan-Phi Nguyen, Yilun Zhou, Chien-Sheng Wu, Caiming Xiong, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides

Variation in Verification: Understanding Verification Dynamics in Large Language Models
Yefan Zhou, Austin Xu, Yilun Zhou, Janvijay Singh, Jiang Gui, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides
Yefan Zhou, Austin Xu, Yilun Zhou, Janvijay Singh, Jiang Gui, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides
On the Shelf Life of Finetuned LLM-Judges: Future Proofing, Backward Compatibility, and Question Generalization
Janvijay Singh, Austin Xu, Yilun Zhou, Yefan Zhou, Dilek Hakkani-Tür, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides
Janvijay Singh, Austin Xu, Yilun Zhou, Yefan Zhou, Dilek Hakkani-Tür, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides

LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
Jiayu Wang, Yifei Ming, Riya Dulepet, Qinglin Chen, Austin Xu, Zixuan Ke, Frederic Sala, Aws Albarghouthi, Caiming Xiong, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides
Jiayu Wang, Yifei Ming, Riya Dulepet, Qinglin Chen, Austin Xu, Zixuan Ke, Frederic Sala, Aws Albarghouthi, Caiming Xiong, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides
SWERank: Software Issue Localization with Code Ranking
Revanth Gangi, Tarun Suresh, JaeHyeok Doo, Ye Liu, Xuan-Phi Nguyen, Yingbo Zhou, Semih Yavuz, Caiming Xiong, Heng Ji, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides
Revanth Gangi, Tarun Suresh, JaeHyeok Doo, Ye Liu, Xuan-Phi Nguyen, Yingbo Zhou, Semih Yavuz, Caiming Xiong, Heng Ji, and Shafiq Joty. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides

References Improve LLM Alignment in Non-Verifiable Domains
Kejian Shi, Yixin Liu, PeiFeng Wang, Alexander Fabbri, Shafiq Joty, and Arman Cohan. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides
Kejian Shi, Yixin Liu, PeiFeng Wang, Alexander Fabbri, Shafiq Joty, and Arman Cohan. In The Fourteenth International Conference on Learning Representations (ICLR-26) 2026.
PDF BibTex Slides

DashboardQA: Benchmarking Multimodal Agents for Question Answering on Interactive Dashboards
Aaryaman Kartha, Ahmed Masry, Mohammed Saidul, Thinh Lang, Shadikur Rahman, Ridwan Mahbub, Mizanur Rahman, Mahir Ahmed, Md Rizwan, Enamul Hoque, and Shafiq Joty. In In 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL-26) 2026.
PDF BibTex Slides
Aaryaman Kartha, Ahmed Masry, Mohammed Saidul, Thinh Lang, Shadikur Rahman, Ridwan Mahbub, Mizanur Rahman, Mahir Ahmed, Md Rizwan, Enamul Hoque, and Shafiq Joty. In In 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL-26) 2026.
PDF BibTex Slides

Aligning Text, Code, and Vision: A Multi-Objective Reinforcement Learning Framework for Text-to-Visualization
Mizanur Rahman, Mohammed Saidul, Md Tahmid, Shafiq Joty, and Enamul Hoque. In In 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL-26) 2026.
PDF BibTex Slides
Mizanur Rahman, Mohammed Saidul, Md Tahmid, Shafiq Joty, and Enamul Hoque. In In 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL-26) 2026.
PDF BibTex Slides
2025

Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning
Jiayu Wang, Yifei Ming, Zixuan Ke, Caiming Xiong, Shafiq Joty, Aws Albarghouthi, and Frederic Sala. In 2025 Conference on Neural Information Processing Systems (NeurIPS'25) 2025.
PDF Abstract BibTex Slides
Jiayu Wang, Yifei Ming, Zixuan Ke, Caiming Xiong, Shafiq Joty, Aws Albarghouthi, and Frederic Sala. In 2025 Conference on Neural Information Processing Systems (NeurIPS'25) 2025.
PDF Abstract BibTex Slides

The Emergence of Abstract Thought in Large Language Models Beyond Any Language
Yuxin Chen, Yiran Zhao, Yang Zhang, Kenji Kawaguchi An Zhang, Shafiq Joty, Junnan Li, Tat-Seng Chua, Michael Qizhe, and Wenxuan Zhang. In 2025 Conference on Neural Information Processing Systems (NeurIPS'25) 2025.
PDF Abstract BibTex Slides
Yuxin Chen, Yiran Zhao, Yang Zhang, Kenji Kawaguchi An Zhang, Shafiq Joty, Junnan Li, Tat-Seng Chua, Michael Qizhe, and Wenxuan Zhang. In 2025 Conference on Neural Information Processing Systems (NeurIPS'25) 2025.
PDF Abstract BibTex Slides
Direct Judgement Preference Optimization
Peifeng Wang, Austin Xu, Yilun Zhou, Caiming Xong, and Shafiq Joty. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
PDF BibTex Slides
Peifeng Wang, Austin Xu, Yilun Zhou, Caiming Xong, and Shafiq Joty. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
PDF BibTex Slides
Demystifying Domain-adaptive Post-training for Financial LLMs
Zixuan Ke, Yifei Ming, Xuan-Phi Nguyen, Caiming Xiong, and Shafiq Joty. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
PDF BibTex Slides
Zixuan Ke, Yifei Ming, Xuan-Phi Nguyen, Caiming Xiong, and Shafiq Joty. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
PDF BibTex Slides

From Charts to Fair Narratives: Uncovering and Mitigating Geo-Economic Biases in Chart-to-Text
Ridwan Mahbub, Mohammed Saidul, Mir Tafseer, Md Tahmid, Mizanur Rahman, Shafiq Joty, and Enamul Hoque. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
PDF BibTex Slides
Ridwan Mahbub, Mohammed Saidul, Mir Tafseer, Md Tahmid, Mizanur Rahman, Shafiq Joty, and Enamul Hoque. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
PDF BibTex Slides
Text2Vis: A Challenging and Diverse Benchmark for Generating Multimodal Visualizations from Text
Mizanur Rahman, Md Tahmid, Shafiq Joty, and Enamul Hoque. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
PDF BibTex Slides
Mizanur Rahman, Md Tahmid, Shafiq Joty, and Enamul Hoque. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
PDF BibTex Slides
CEMTM: Contextual Embedding-based Multimodal Topic Modeling
Amirhossein Abaskohi, Raymond Li, Chuyuan Li, Shafiq Joty, and Giuseppe Carenini. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
BibTex Slides
Amirhossein Abaskohi, Raymond Li, Chuyuan Li, Shafiq Joty, and Giuseppe Carenini. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25) 2025.
BibTex Slides
Topic-Guided Reinforcement Learning with LLMs for Enhancing Multi-Document Summarization
Chuyuan Li, Austin Xu, Shafiq Joty, and Giuseppe Carenini. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25 Findings) 2025.
BibTex Slides
Chuyuan Li, Austin Xu, Shafiq Joty, and Giuseppe Carenini. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-25 Findings) 2025.
BibTex Slides

CodeXEmbed: A Generalist Embedding Model Family for Multilingual and Multi-task Code Retrieval
Ye Liu, Rui Meng, Shafiq Joty, Silvio Savarese, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. In Second Conference on Language Modeling (COLM-25) 2025.
PDF BibTex Slides
Ye Liu, Rui Meng, Shafiq Joty, Silvio Savarese, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. In Second Conference on Language Modeling (COLM-25) 2025.
PDF BibTex Slides
Evaluating Judges as Evaluators: The JETTS Benchmark of LLM-as-Judges as Test-Time Scaling Evaluators
Zhou Yilun, Xu Austin, Wang Peifeng, Xiong Caiming, and Joty Shafiq. In International Conference on Machine Learning (ICML-25) 2025.
PDF BibTex Slides
Zhou Yilun, Xu Austin, Wang Peifeng, Xiong Caiming, and Joty Shafiq. In International Conference on Machine Learning (ICML-25) 2025.
PDF BibTex Slides
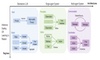
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan, Minzhi Li, Chengwei Qin, Peifeng Wang, Silvio Savarese, Caiming Xiong, and Shafiq Joty. In Transactions on Machine Learning Research (TMLR) 2025.
PDF BibTex Slides
Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan, Minzhi Li, Chengwei Qin, Peifeng Wang, Silvio Savarese, Caiming Xiong, and Shafiq Joty. In Transactions on Machine Learning Research (TMLR) 2025.
PDF BibTex Slides
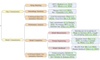
How Much are LLMs Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mathieu Ravaut, Bosheng Ding, Fangkai Jiao, Hailin Chen, Xingxuan Li, Ruochen Zhao, Chengwei Qin, Caiming Xiong, and Shafiq Joty. In Transactions on Machine Learning Research (TMLR) 2025.
PDF Abstract BibTex Slides
Mathieu Ravaut, Bosheng Ding, Fangkai Jiao, Hailin Chen, Xingxuan Li, Ruochen Zhao, Chengwei Qin, Caiming Xiong, and Shafiq Joty. In Transactions on Machine Learning Research (TMLR) 2025.
PDF Abstract BibTex Slides

Generalized Out-of-Distribution Detection and Beyond in Vision Language Model Era: A Survey
Atsuyuki Miyai, Jingkang Yang, Jingyang Zhang, Yifei Ming, Yueqian Lin, Qing Yu, Go Irie, Shafiq Joty, Yixuan Li, Hai Li, Ziwei Liu, Toshihiko Yamasaki, and Kiyoharu Aizawa. In Transactions on Machine Learning Research (TMLR) 2025.
PDF BibTex Slides
Atsuyuki Miyai, Jingkang Yang, Jingyang Zhang, Yifei Ming, Yueqian Lin, Qing Yu, Go Irie, Shafiq Joty, Yixuan Li, Hai Li, Ziwei Liu, Toshihiko Yamasaki, and Kiyoharu Aizawa. In Transactions on Machine Learning Research (TMLR) 2025.
PDF BibTex Slides

Does Context Matter? ContextualJudgeBench for Evaluating LLM-based Judges in Contextual Settings
Austin Xu, Srijan Bansal, Yifei Ming, Semih Yavuz, and Shafiq Joty. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
PDF BibTex Slides
Austin Xu, Srijan Bansal, Yifei Ming, Semih Yavuz, and Shafiq Joty. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
PDF BibTex Slides

What Makes a Good Natural Language Prompt?
Do-Xuan Long, Duy Dinh, Ngoc-Hai Nguyen, Kenji Kawaguchi, Nancy Chen, Shafiq Joty, and Min-Yen Kan. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
BibTex Slides
Do-Xuan Long, Duy Dinh, Ngoc-Hai Nguyen, Kenji Kawaguchi, Nancy Chen, Shafiq Joty, and Min-Yen Kan. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
BibTex Slides

Can We Further Elicit Reasoning in LLMs? Critic-Guided Planning with Retrieval-Augmentation for Solving Challenging Tasks
Xingxuan Li, Weiwen Xu, Ruochen Zhao, Fangkai Jiao, Shafiq Joty, and Lidong Bing. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
PDF BibTex Slides
Xingxuan Li, Weiwen Xu, Ruochen Zhao, Fangkai Jiao, Shafiq Joty, and Lidong Bing. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
PDF BibTex Slides

Beyond Output Matching: Bidirectional Alignment for Enhanced In-Context Learning
Chengwei Qin, Wenhan Xia, Fangkai Jiao, Chen Chen, Yuchen Hu, Bosheng Ding, Ruirui Chen, and Shafiq Joty. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
PDF BibTex Slides
Chengwei Qin, Wenhan Xia, Fangkai Jiao, Chen Chen, Yuchen Hu, Bosheng Ding, Ruirui Chen, and Shafiq Joty. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
PDF BibTex Slides
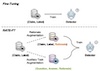
Learning Auxiliary Tasks Improves Reference-Free Hallucination Detection in Open-Domain Long-Form Generation
Chengwei Qin, Wenxuan Zhou, Karthik Sankararaman, Nanshu Wang, Tengyu Xu, Alexander Radovic, Eryk Helenowski, Arya Talebzadeh, Aditya Tayade, Sinong Wang, Shafiq Joty, Han Fang, and Hao Ma. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
PDF BibTex Slides
Chengwei Qin, Wenxuan Zhou, Karthik Sankararaman, Nanshu Wang, Tengyu Xu, Alexander Radovic, Eryk Helenowski, Arya Talebzadeh, Aditya Tayade, Sinong Wang, Shafiq Joty, Han Fang, and Hao Ma. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25) 2025.
PDF BibTex Slides

ChartQAPro: A More Diverse and Challenging Benchmark for Chart Question Answering
Ahmed Masry, Mohammed Islam, Mahir Ahmed, Aayush Bajaj, Firoz Kabir, Aaryaman Kartha, Tahmid Laskar, Mizanur Rahman, Shadikur Rahman, Mehrad Shahmohammadi, Megh Thakkar, Rizwan Parvez, Enamul Hoque, and Shafiq Joty. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 Findings) 2025.
PDF BibTex Slides
Ahmed Masry, Mohammed Islam, Mahir Ahmed, Aayush Bajaj, Firoz Kabir, Aaryaman Kartha, Tahmid Laskar, Mizanur Rahman, Shadikur Rahman, Mehrad Shahmohammadi, Megh Thakkar, Rizwan Parvez, Enamul Hoque, and Shafiq Joty. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 Findings) 2025.
PDF BibTex Slides

Relevant or Random: Can LLMs Truly Perform Analogical Reasoning?
Chengwei Qin, Wenhan Xia, Tan Wang, Fangkai Jiao, Yuchen Hu, Bosheng Ding, Ruirui Chen, and Shafiq Joty. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 Findings) 2025.
PDF BibTex Slides
Chengwei Qin, Wenhan Xia, Tan Wang, Fangkai Jiao, Yuchen Hu, Bosheng Ding, Ruirui Chen, and Shafiq Joty. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 Findings) 2025.
PDF BibTex Slides

Beyond In-Context Learning: Aligning Long-form Generation of Large Language Models via Task-Inherent Attribute Guidelines
Do Xuan, Duong Yen, Do Xuan, Anh Tuan, Kenji Kawaguchi, Shafiq Joty, Min-Yen Kan, and Nancy Chen. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 Findings) 2025.
PDF BibTex Slides
Do Xuan, Duong Yen, Do Xuan, Anh Tuan, Kenji Kawaguchi, Shafiq Joty, Min-Yen Kan, and Nancy Chen. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 Findings) 2025.
PDF BibTex Slides

Why Vision Language Models Struggle with Visual Arithmetic? Towards Enhanced Chart and Geometry Understanding
Kung-Hsiang Huang, Can Qin, Haoyi Qiu, Philippe Laban, Shafiq Joty, Caiming Xiong, and Chien-Sheng Wu. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 Findings) 2025.
PDF BibTex Slides
Kung-Hsiang Huang, Can Qin, Haoyi Qiu, Philippe Laban, Shafiq Joty, Caiming Xiong, and Chien-Sheng Wu. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 Findings) 2025.
PDF BibTex Slides

Judging the Judges: Can Large Vision-Language Models Fairly Evaluate Chart Comprehension and Reasoning?
Tahmid Laskar, Mohammed Islam, Ridwan Mahbub, Ahmed Masry, Mizanur Rahman, Amran Bhuiyan, Mir Nayeem, Shafiq Joty, Enamul Hoque, and Jimmy Huang. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 (Industry track)) 2025.
PDF BibTex Slides
Tahmid Laskar, Mohammed Islam, Ridwan Mahbub, Ahmed Masry, Mizanur Rahman, Amran Bhuiyan, Mir Nayeem, Shafiq Joty, Enamul Hoque, and Jimmy Huang. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL-25 (Industry track)) 2025.
PDF BibTex Slides
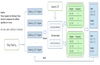
Preference Optimization for Reasoning with Pseudo Feedback
Fangkai Jiao, Geyang Guo, Xingxing Zhang, Nancy F., Shafiq Joty, and Furu Wei. In International Conference on Learning Representations (ICLR-25 spotlight) 2025.
PDF BibTex Slides
Fangkai Jiao, Geyang Guo, Xingxing Zhang, Nancy F., Shafiq Joty, and Furu Wei. In International Conference on Learning Representations (ICLR-25 spotlight) 2025.
PDF BibTex Slides
FaithEval: Can Your Language Model Stay Faithful to Context, Even If "The Moon is Made of Marshmallows"
Yifei Ming, Senthil Purushwalkam, Shrey Pandit, Zixuan Ke, Xuan-Phi Nguyen, Caiming Xiong, and Shafiq Joty. In International Conference on Learning Representations (ICLR-25) 2025.
PDF BibTex Slides
Yifei Ming, Senthil Purushwalkam, Shrey Pandit, Zixuan Ke, Xuan-Phi Nguyen, Caiming Xiong, and Shafiq Joty. In International Conference on Learning Representations (ICLR-25) 2025.
PDF BibTex Slides

On Positional Bias of Faithfulness for Long-form Summarization
David Wan, Jesse Vig, Mohit Bansal, and Shafiq Joty. In 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-25) 2025.
PDF Abstract BibTex Slides
David Wan, Jesse Vig, Mohit Bansal, and Shafiq Joty. In 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-25) 2025.
PDF Abstract BibTex Slides

ReIFE: Re-evaluating Instruction-Following Evaluation
Yixin Liu, Kejian Shi, Alexander Fabbri, Yilun Zhao, Peifeng Wang, Chien-Sheng Wu, Shafiq Joty, and Arman Cohan. In 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-25) 2025.
PDF Abstract BibTex Slides
Yixin Liu, Kejian Shi, Alexander Fabbri, Yilun Zhao, Peifeng Wang, Chien-Sheng Wu, Shafiq Joty, and Arman Cohan. In 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-25) 2025.
PDF Abstract BibTex Slides
ParaICL: Towards Robust Parallel In-Context Learning
Xingxuan Li, Xuan-Phi Nguyen, Shafiq Joty, and Lidong Bing. In 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-25) 2025.
PDF Abstract BibTex Slides
Xingxuan Li, Xuan-Phi Nguyen, Shafiq Joty, and Lidong Bing. In 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-25) 2025.
PDF Abstract BibTex Slides

LLMs Are Biased Towards Output Formats! Systematically Evaluating and Mitigating Output Format Bias of LLMs
Do Long, Hai Ngoc, Tiviatis Sim, Hieu Dao, Shafiq Joty, Kenji Kawaguchi, Nancy Chen, and Min-Yen Kan. In 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-25) 2025.
PDF Abstract BibTex Slides
Do Long, Hai Ngoc, Tiviatis Sim, Hieu Dao, Shafiq Joty, Kenji Kawaguchi, Nancy Chen, and Min-Yen Kan. In 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-25) 2025.
PDF Abstract BibTex Slides

Adaptation of Large Language Models
Zixuan Ke, Yifei Ming, and Shafiq Joty. In 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 5: Tutorial Abstracts) (NAACL-25) , pages 30-37, 2025.
PDF Abstract BibTex Slides
Zixuan Ke, Yifei Ming, and Shafiq Joty. In 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 5: Tutorial Abstracts) (NAACL-25) , pages 30-37, 2025.
PDF Abstract BibTex Slides

DnA-Eval: Enhancing Large Language Model Evaluation through Decomposition and Aggregation
Minzhi Li, Zhengyuan Liu, Shumin Deng, Shafiq Joty, Nancy Chen, and Min-Yen Kan. In Proceedings of the 31st International Conference on Computational Linguistics (COLING-25) 2025.
PDF Abstract BibTex Slides
Minzhi Li, Zhengyuan Liu, Shumin Deng, Shafiq Joty, Nancy Chen, and Min-Yen Kan. In Proceedings of the 31st International Conference on Computational Linguistics (COLING-25) 2025.
PDF Abstract BibTex Slides
ChartGemma: Visual Instruction-tuning for Chart Reasoning in the Wild
Ahmed Masry, Megh Thakkar, Aayush Bajaj, Aaryaman Kartha, Enamul Hoque, and Shafiq Joty. In Proceedings of the 31st International Conference on Computational Linguistics (COLING-25) 2025.
PDF Abstract BibTex Slides
Ahmed Masry, Megh Thakkar, Aayush Bajaj, Aaryaman Kartha, Enamul Hoque, and Shafiq Joty. In Proceedings of the 31st International Conference on Computational Linguistics (COLING-25) 2025.
PDF Abstract BibTex Slides
2024

Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing (Outstanding paper award)
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy Chen, and Shafiq Joty. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy Chen, and Shafiq Joty. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides

DataNarrative: Automated Data-Driven Storytelling with Visualizations and Texts
Mohammed Islam, Md Laskar, Md Parvez, Enamul Hoque, and Shafiq Joty. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides
Mohammed Islam, Md Laskar, Md Parvez, Enamul Hoque, and Shafiq Joty. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides

Evaluating Psychological Safety of Large Language Models
Xingxuan Li, Yutong Li, Lin Qiu, Shafiq Joty, and Lidong Bing. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides
Xingxuan Li, Yutong Li, Lin Qiu, Shafiq Joty, and Lidong Bing. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides

FOLIO: Natural Language Reasoning with First-Order Logic
SIMENG HAN, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alexander Wardle-Solano, Hannah Szabó, Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander Fabbri, Wojciech Maciej, Semih Yavuz, Ye Liu, Victoria Lin, Shafiq Joty, Yingbo Zhou, Caiming Xiong, Rex Ying, Arman Cohan, and Dragomir Radev. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides
SIMENG HAN, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alexander Wardle-Solano, Hannah Szabó, Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander Fabbri, Wojciech Maciej, Semih Yavuz, Ye Liu, Victoria Lin, Shafiq Joty, Yingbo Zhou, Caiming Xiong, Rex Ying, Arman Cohan, and Dragomir Radev. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides

A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations
Md Laskar, Sawsan Alqahtani, M Bari, Mizanur Rahman, Mohammad Khan, Haidar Khan, Israt Jahan, Amran Bhuiyan, Chee Tan, Md Parvez, Enamul Hoque, Shafiq Joty, and Jimmy Huang. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides
Md Laskar, Sawsan Alqahtani, M Bari, Mizanur Rahman, Mohammad Khan, Haidar Khan, Israt Jahan, Amran Bhuiyan, Chee Tan, Md Parvez, Enamul Hoque, Shafiq Joty, and Jimmy Huang. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24) 2024.
PDF Abstract BibTex Slides
Open-RAG: Enhanced Retrieval Augmented Reasoning with Open-Source Large Language Models
Shayekh Islam, Md Rahman, K Hossain, Enamul Hoque, Shafiq Joty, and Md Parvez. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24 Findings) 2024.
PDF Abstract BibTex Slides
Shayekh Islam, Md Rahman, K Hossain, Enamul Hoque, Shafiq Joty, and Md Parvez. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24 Findings) 2024.
PDF Abstract BibTex Slides
Investigating the prompt leakage effect and black-box defenses for multi-turn LLM interactions
Divyansh Agarwal, Alexander Fabbri, Philippe Laban, Shafiq Joty, Caiming Xiong, and Chien-Sheng Wu. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24 Industry Track) 2024.
PDF Abstract BibTex Slides
Divyansh Agarwal, Alexander Fabbri, Philippe Laban, Shafiq Joty, Caiming Xiong, and Chien-Sheng Wu. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24 Industry Track) 2024.
PDF Abstract BibTex Slides
P-FOLIO: Evaluating and Improving Logical Reasoning with Abundant Human-Written Reasoning Chains
SIMENG HAN, Aaron Yu, Rui Shen, Zhenting Qi, Martin Riddell, Wenfei Zhou, Yujie Qiao, Yilun Zhao, Semih Yavuz, Ye Liu, Shafiq Joty, Yingbo Zhou, Caiming Xiong, Rex Ying, Arman Cohan, and Dragomir Radev. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24 Findings) 2024.
PDF Abstract BibTex Slides
SIMENG HAN, Aaron Yu, Rui Shen, Zhenting Qi, Martin Riddell, Wenfei Zhou, Yujie Qiao, Yilun Zhao, Semih Yavuz, Ye Liu, Shafiq Joty, Yingbo Zhou, Caiming Xiong, Rex Ying, Arman Cohan, and Dragomir Radev. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP'24 Findings) 2024.
PDF Abstract BibTex Slides
X-InstructBLIP: A Framework for aligning X-Modal instruction-aware representations to LLMs and Emergent Cross-modal Reasoning
Artemis Panagopoulou, Le Xue, Ning Yu, Junnan Li, Dongxu Li, Shafiq Joty, Ran Xu, Silvio Savarese, Caiming Xiong, and Juan-Carlos Niebles. In 2024 European Conference on Computer Vision (ECCV'24) 2024.
PDF Abstract BibTex Slides
Artemis Panagopoulou, Le Xue, Ning Yu, Junnan Li, Dongxu Li, Shafiq Joty, Ran Xu, Silvio Savarese, Caiming Xiong, and Juan-Carlos Niebles. In 2024 European Conference on Computer Vision (ECCV'24) 2024.
PDF Abstract BibTex Slides
XCodeEval: An Execution-based Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval
Mohammad Khan, M Bari, Do Long, Weishi Wang, Md Parvez, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24) 2024.
PDF Abstract BibTex Slides
Mohammad Khan, M Bari, Do Long, Weishi Wang, Md Parvez, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24) 2024.
PDF Abstract BibTex Slides

On Context Utilization in Summarization with Large Language Models
Mathieu Ravaut, Aixin Sun, Nancy Chen, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24) 2024.
PDF Abstract BibTex Slides
Mathieu Ravaut, Aixin Sun, Nancy Chen, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24) 2024.
PDF Abstract BibTex Slides

Democratizing LLMs for Low-Resource Languages by Leveraging their English Dominant Abilities with Linguistically-Diverse Prompts
Xuan-Phi Nguyen, Mahani Aljunied, Shafiq Joty, and Lidong Bing. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24) 2024.
PDF Abstract BibTex Slides
Xuan-Phi Nguyen, Mahani Aljunied, Shafiq Joty, and Lidong Bing. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24) 2024.
PDF Abstract BibTex Slides

ChartInstruct: Instruction Tuning for Chart Comprehension and Reasoning
Ahmed Masry, Mehrad Shahmohammadi, Md Parvez, Enamul Hoque, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24 Findings) 2024.
PDF Abstract BibTex Slides
Ahmed Masry, Mehrad Shahmohammadi, Md Parvez, Enamul Hoque, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24 Findings) 2024.
PDF Abstract BibTex Slides

Data Augmentation using LLMs: Methods, Learning Paradigms and Challenges
Bosheng Ding, Chengwei Qin, Ruochen Zhao, Tianze Luo, Xinze Li, Guizhen Chen, Wenhan Xia, Junjie Hu, Anh-Tuan Luu, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24 Findings) 2024.
PDF Abstract BibTex Slides
Bosheng Ding, Chengwei Qin, Ruochen Zhao, Tianze Luo, Xinze Li, Guizhen Chen, Wenhan Xia, Junjie Hu, Anh-Tuan Luu, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24 Findings) 2024.
PDF Abstract BibTex Slides

XL-HeadTags: Leveraging Multimodal Retrieval Augmentation for the Multilingual Generation of News Headlines and Tags
Faisal Shohan, Mir Nayeem, Samsul Islam, Abu Akash, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24 Findings) 2024.
Abstract BibTex Slides
Faisal Shohan, Mir Nayeem, Samsul Islam, Abu Akash, and Shafiq Joty. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24 Findings) 2024.
Abstract BibTex Slides

Embrace Divergence for Richer Insights: A Multi-document Summarization Benchmark and a Case Study on Summarizing Diverse Information from News Articles
Kung-Hsiang Huang, Philippe Laban, Alexander Fabbri, Prafulla Kumar, Shafiq Joty, Caiming Xiong, and Chien-Sheng Wu. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24) 2024.
PDF Abstract BibTex Slides
Kung-Hsiang Huang, Philippe Laban, Alexander Fabbri, Prafulla Kumar, Shafiq Joty, Caiming Xiong, and Chien-Sheng Wu. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24) 2024.
PDF Abstract BibTex Slides
Exploring Self-supervised Logic-enhanced Training for Large Language Models
Fangkai Jiao, Zhiyang Teng, Bosheng Ding, Zhengyuan Liu, Nancy Chen, and Shafiq Joty. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24) 2024.
PDF Abstract BibTex Slides
Fangkai Jiao, Zhiyang Teng, Bosheng Ding, Zhengyuan Liu, Nancy Chen, and Shafiq Joty. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24) 2024.
PDF Abstract BibTex Slides
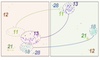
Lifelong Event Detection with Embedding Space Separation and Compaction
Chengwei Qin, Ruirui Chen, Ruochen Zhao, Wenhan Xia, and Shafiq Joty. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24) 2024.
PDF Abstract BibTex Slides
Chengwei Qin, Ruirui Chen, Ruochen Zhao, Wenhan Xia, and Shafiq Joty. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24) 2024.
PDF Abstract BibTex Slides

Benchmarking Generation and Evaluation Capabilities of Large Language Models for Instruction Controllable Summarization
Yixin Liu, Alexander Fabbri, Jiawen Chen, Yilun Zhao, SIMENG HAN, Shafiq Joty, Pengfei Liu, Dragomir Radev, Chien-Sheng Wu, and Arman Cohan. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24 Findings) 2024.
PDF Abstract BibTex Slides
Yixin Liu, Alexander Fabbri, Jiawen Chen, Yilun Zhao, SIMENG HAN, Shafiq Joty, Pengfei Liu, Dragomir Radev, Chien-Sheng Wu, and Arman Cohan. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24 Findings) 2024.
PDF Abstract BibTex Slides
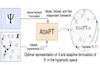
AdaPT: A Set of Guidelines for Hyperbolic Multimodal Multilingual NLP
Ramit Sawhney, Megh Thakkar, Vishwa Shah, Shrey Pandit, and Shafiq Joty. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24 Findings) 2024.
PDF Abstract BibTex Slides
Ramit Sawhney, Megh Thakkar, Vishwa Shah, Shrey Pandit, and Shafiq Joty. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24 Findings) 2024.
PDF Abstract BibTex Slides

DIVKNOWQA: Assessing the Reasoning Ability of LLMs via Open-Domain Question Answering over Knowledge Base and Text
Wenting Zhao, Ye Liu, Tong Niu, Yao Wan, Philip Yu, Shafiq Joty, Yingbo Zhou, and Semih Yavuz. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24 Findings) 2024.
PDF Abstract BibTex Slides
Wenting Zhao, Ye Liu, Tong Niu, Yao Wan, Philip Yu, Shafiq Joty, Yingbo Zhou, and Semih Yavuz. In 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-24 Findings) 2024.
PDF Abstract BibTex Slides

Diffusion Model Alignment Using Direct Preference Optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. In International Conference on Computer Vision and Pattern Recognition (CVPR-24) 2024.
PDF Abstract BibTex Slides
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. In International Conference on Computer Vision and Pattern Recognition (CVPR-24) 2024.
PDF Abstract BibTex Slides
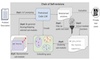
CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules
Hung Le, Hailin Chen, Amrita Saha, Akash Gokul, Doyen Sahoo, and Shafiq Joty. In International Conference on Learning Representations (ICLR-24) 2024.
PDF Abstract BibTex Slides
Hung Le, Hailin Chen, Amrita Saha, Akash Gokul, Doyen Sahoo, and Shafiq Joty. In International Conference on Learning Representations (ICLR-24) 2024.
PDF Abstract BibTex Slides
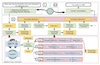
Chain of Knowledge: A Framework for Grounding Large Language Models with Structured Knowledge Bases
Xingxuan Li, Ruochen Zhao, Yew Ken, Bosheng Ding, Shafiq Joty, Soujanya Poria, and Lidong Bing. In International Conference on Learning Representations (ICLR-24) 2024.
PDF Abstract BibTex Slides
Xingxuan Li, Ruochen Zhao, Yew Ken, Bosheng Ding, Shafiq Joty, Soujanya Poria, and Lidong Bing. In International Conference on Learning Representations (ICLR-24) 2024.
PDF Abstract BibTex Slides
L2CEval: Evaluating Language-to-Code Generation Capabilities of Large Language Models
Ansong Ni, Pengcheng Yin, Yilun Zhao, Martin Riddell, Troy Feng, Rui Shen, Stephen Yin, Ye Liu, Semih Yavuz, Caiming Xiong, Shafiq Joty, Yingbo Zhou, Dragomir Radev, and Arman Cohan. In Transactions of ACL (TACL) 2024.
PDF Abstract BibTex
Ansong Ni, Pengcheng Yin, Yilun Zhao, Martin Riddell, Troy Feng, Rui Shen, Stephen Yin, Ye Liu, Semih Yavuz, Caiming Xiong, Shafiq Joty, Yingbo Zhou, Dragomir Radev, and Arman Cohan. In Transactions of ACL (TACL) 2024.
PDF Abstract BibTex

From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
Kung-Hsiang Huang, Hou Chan, Yi Fung, Haoyi Qiu, Mingyang Zhou, Shafiq Joty, Shih-Fu Chang, and Heng Ji. In IEEE Transactions on Knowledge and Data Engineering (TKDE) 2024.
PDF Abstract BibTex
Kung-Hsiang Huang, Hou Chan, Yi Fung, Haoyi Qiu, Mingyang Zhou, Shafiq Joty, Shih-Fu Chang, and Heng Ji. In IEEE Transactions on Knowledge and Data Engineering (TKDE) 2024.
PDF Abstract BibTex
Improving conversational recommender system via contextual and time-aware modeling with less domain-specific knowledge
Lingzhi Wang, Shafiq Joty, Wei Gao, Xingshan Zeng, and Kam-Fai Wong. In IEEE Transactions on Knowledge and Data Engineering (TKDE) 2024.
PDF Abstract BibTex
Lingzhi Wang, Shafiq Joty, Wei Gao, Xingshan Zeng, and Kam-Fai Wong. In IEEE Transactions on Knowledge and Data Engineering (TKDE) 2024.
PDF Abstract BibTex
Explaining Language Model Predictions with High-Impact Concepts
Ruochen Zhao, Shafiq Joty, Yongjie Wang, and Tan Wang. In Findings of ACL (EACL-24) 2024.
PDF Abstract BibTex Slides
Ruochen Zhao, Shafiq Joty, Yongjie Wang, and Tan Wang. In Findings of ACL (EACL-24) 2024.
PDF Abstract BibTex Slides
Efficiently Aligned Cross-Lingual Transfer Learning for Conversational Tasks using Prompt-Tuning
Lifu Tu, Jin Qu, Semih Yavuz, Shafiq Joty, Wenhao Liu, Caiming Xiong, and Yingbo Zhou. In In Findings of ACL (EACL-24) 2024.
PDF Abstract BibTex Slides
Lifu Tu, Jin Qu, Semih Yavuz, Shafiq Joty, Wenhao Liu, Caiming Xiong, and Yingbo Zhou. In In Findings of ACL (EACL-24) 2024.
PDF Abstract BibTex Slides
2023
Personalized Distillation: Empowering Open-Sourced LLMs with Adaptive Learning for Code Generation
Hailin Chen, Amrita Saha, Shafiq Joty, and Steven Hoi. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
Abstract BibTex Slides
Hailin Chen, Amrita Saha, Shafiq Joty, and Steven Hoi. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
Abstract BibTex Slides
Lifelong Sequence Generation with Dynamic Module Expansion and Adaptation
Chengwei Qin, Shafiq Joty, and CHEN CHEN. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
Abstract BibTex Slides
Chengwei Qin, Shafiq Joty, and CHEN CHEN. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
Abstract BibTex Slides

UniChart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning
Ahmed Masry, Parsa Kavehzadeh, Do Long, Enamul Hoque, and Shafiq Joty. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
PDF Abstract BibTex Slides
Ahmed Masry, Parsa Kavehzadeh, Do Long, Enamul Hoque, and Shafiq Joty. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
PDF Abstract BibTex Slides
Towards Low-Resource Automatic Program Repair with Meta-Learning and Pretrained Language Models
Weishi Wang, Yue Wang, Shafiq Joty, and Steven Hoi. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
Abstract BibTex Slides
Weishi Wang, Yue Wang, Shafiq Joty, and Steven Hoi. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
Abstract BibTex Slides

SummEdits: Measuring LLM Ability at Factual Reasoning Through The Lens of Summarization
Philippe Laban, Wojciech Kryscinski, Divyansh Agarwal, Alexander Fabbri, Caiming Xiong, Shafiq Joty, and Chien-Sheng Wu. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
PDF Abstract BibTex Slides
Philippe Laban, Wojciech Kryscinski, Divyansh Agarwal, Alexander Fabbri, Caiming Xiong, Shafiq Joty, and Chien-Sheng Wu. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
PDF Abstract BibTex Slides
Towards Interpretable and Efficient Automatic Reference-Based Summarization Evaluation
Yixin Liu, Alex Fabbri, Pengfei Liu, Shafiq Joty, Chien-Sheng Wu, Caiming Xiong, and Dragomir Radev. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
PDF Abstract BibTex Slides
Yixin Liu, Alex Fabbri, Pengfei Liu, Shafiq Joty, Chien-Sheng Wu, Caiming Xiong, and Dragomir Radev. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23) 2023.
PDF Abstract BibTex Slides

Retrieving Multimodal Information for Augmented Generation: A Survey
Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Do Long, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, and Shafiq Joty. In Findings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23 Findings) 2023.
PDF Abstract BibTex Slides
Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Do Long, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, and Shafiq Joty. In Findings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23 Findings) 2023.
PDF Abstract BibTex Slides
HPE: Answering Complex Questions over Text by Hybrid Question Parsing and Execution
Ye Liu, Semih Yavuz, Rui Meng, Dragomir Radev, Caiming Xiong, Shafiq Joty, and Yingbo Zhou. In Findings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23 Findings) 2023.
Abstract BibTex Slides
Ye Liu, Semih Yavuz, Rui Meng, Dragomir Radev, Caiming Xiong, Shafiq Joty, and Yingbo Zhou. In Findings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP'23 Findings) 2023.
Abstract BibTex Slides
Verify-and-Edit: A Knowledge-Enhanced Chain-of-Thought Framework
Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, and Lidong Bing. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, and Lidong Bing. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides

Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning
Fan Yin, Jesse Vig, Philippe Laban, Shafiq Joty, Caiming Xiong, and Chien-Sheng Jason. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
Abstract BibTex Slides
Fan Yin, Jesse Vig, Philippe Laban, Shafiq Joty, Caiming Xiong, and Chien-Sheng Jason. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
Abstract BibTex Slides

Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation
Yixin Liu, Alex Fabbri, Pengfei Liu, Yilun Zhao, Linyong Nan, Ruilin Han, Simeng Han, Shafiq Joty, Chien-Sheng Jason, Caiming Xiong, and Dragomir Radev. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Yixin Liu, Alex Fabbri, Pengfei Liu, Yilun Zhao, Linyong Nan, Ruilin Han, Simeng Han, Shafiq Joty, Chien-Sheng Jason, Caiming Xiong, and Dragomir Radev. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides

SWiPE: A Dataset for Document-Level Simplification of Wikipedia Pages
Philippe Laban, Jesse Vig, Wojciech Kryscinski, Shafiq Joty, Caiming Xiong, and Chien-Sheng Jason. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Philippe Laban, Jesse Vig, Wojciech Kryscinski, Shafiq Joty, Caiming Xiong, and Chien-Sheng Jason. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Randomized Smoothing with Masked Inference for Adversarially Robust Text Classification
Han Cheol, Shafiq Joty, Ruochen Zhao, Megh Thakkar, and Chi Xu. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Han Cheol, Shafiq Joty, Ruochen Zhao, Megh Thakkar, and Chi Xu. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Learning to Initialize: Can Meta Learning Improve Cross-task Generalization in Prompt Tuning?
Chengwei Qin, Shafiq Joty, Qian Li, and Ruochen Zhao. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Chengwei Qin, Shafiq Joty, Qian Li, and Ruochen Zhao. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Towards Robust Low-Resource Fine-Tuning with Multi-View Compressed Representations
Linlin Liu, Xingxuan Li, Megh Thakkar, Xin Li, Shafiq Joty, Luo Si, and Lidong Bing. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Linlin Liu, Xingxuan Li, Megh Thakkar, Xin Li, Shafiq Joty, Luo Si, and Lidong Bing. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Is GPT-3 a Good Data Annotator?
BOSHENG DING, Chengwei Qin, Linlin Liu, Yew Ken, Lidong Bing, Boyang Li, and Shafiq Joty. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
BOSHENG DING, Chengwei Qin, Linlin Liu, Yew Ken, Lidong Bing, Boyang Li, and Shafiq Joty. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Modeling What-to-ask and How-to-ask for Answer-unaware Conversational Question Generation
Xuan Long, Bowei Zou, Shafiq Joty, Tran Tai, Liangming Pan, Nancy Chen, and Ai Ti. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Xuan Long, Bowei Zou, Shafiq Joty, Tran Tai, Liangming Pan, Nancy Chen, and Ai Ti. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides

A Systematic Study of ChatGPT on Benchmark Datasets
Md Tahmid, M Saiful, Mizanur Rahman, Md Amran, Shafiq Joty, and Jimmy Huang. In Findings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23 Findings) 2023.
PDF Abstract BibTex Slides
Md Tahmid, M Saiful, Mizanur Rahman, Md Amran, Shafiq Joty, and Jimmy Huang. In Findings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23 Findings) 2023.
PDF Abstract BibTex Slides
Contrastive Learning with Generated Representations for Inductive Knowledge Graph Embedding
Qian Li, Shafiq Joty, Daling Wang, Shi Feng, Yifei Zhang, and Chengwei Qin. In Findings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23 Findings) 2023.
Abstract BibTex Slides
Qian Li, Shafiq Joty, Daling Wang, Shi Feng, Yifei Zhang, and Chengwei Qin. In Findings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23 Findings) 2023.
Abstract BibTex Slides
Unsupervised Summarization Re-ranking
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. In Findings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23 Findings) 2023.
PDF Abstract BibTex Slides
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. In Findings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23 Findings) 2023.
PDF Abstract BibTex Slides

Efficient Text-to-Code Retrieval with Cascaded Fast and Slow Transformer Models
Akhilesh Gotmare, Junnan Li, Shafiq Joty, and Steven Hoi. In ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2023) 2023.
PDF Abstract BibTex Slides
Akhilesh Gotmare, Junnan Li, Shafiq Joty, and Steven Hoi. In ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2023) 2023.
PDF Abstract BibTex Slides
RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair
Weishi Wang, Yue Wang, Shafiq Joty, and Steven Hoi. In ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2023) 2023.
PDF Abstract BibTex Slides
Weishi Wang, Yue Wang, Shafiq Joty, and Steven Hoi. In ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2023) 2023.
PDF Abstract BibTex Slides

Long Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length
Erik Nijkamp*, Tian Xie*, Hiroaki Hayashi*, Bo Pang*, Congying Xia*, Chen Xing, Jesse Vig, Semih Yavuz, Philippe Laban, Ben Krause, Senthil Purushwalkam, Tong Niu, Wojciech Kryscinski, Lidiya Murakhovs'ka, Prafulla Choubey, Alex Fabbri, Ye Liu, Rui Meng, Lifu Tu, Meghana Bhat, Chien-Sheng Wu, Silvio Savarese, Yingbo Zhou, Shafiq Joty+, and Caiming Xiong+. In 2023.
PDF Abstract BibTex Slides
Erik Nijkamp*, Tian Xie*, Hiroaki Hayashi*, Bo Pang*, Congying Xia*, Chen Xing, Jesse Vig, Semih Yavuz, Philippe Laban, Ben Krause, Senthil Purushwalkam, Tong Niu, Wojciech Kryscinski, Lidiya Murakhovs'ka, Prafulla Choubey, Alex Fabbri, Ye Liu, Rui Meng, Lifu Tu, Meghana Bhat, Chien-Sheng Wu, Silvio Savarese, Yingbo Zhou, Shafiq Joty+, and Caiming Xiong+. In 2023.
PDF Abstract BibTex Slides

NLP+Vis: NLP Meets Visualization
Shafiq Joty, Enamul Hoque, and Jesse Vig. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts (EMNLP'23 Tutorial) , pages 1-6, 2023.
PDF Abstract BibTex Slides
Shafiq Joty, Enamul Hoque, and Jesse Vig. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts (EMNLP'23 Tutorial) , pages 1-6, 2023.
PDF Abstract BibTex Slides
2022

SleepQA: A Health Coaching Dataset on Sleep for Extractive Question Answering
Iva Bojic, Qi Ong, Megh Thakkar, Esha Kamran, Irving Shua, Rei Pang, Jessica Chen, Vaaruni Nayak, Shafiq Joty, and Josip Car. In 2022 Machine Learning for Health (Proceedings Track) (ML4H@NeurIPS'22) 2022.
PDF Abstract BibTex Slides
Iva Bojic, Qi Ong, Megh Thakkar, Esha Kamran, Irving Shua, Rei Pang, Jessica Chen, Vaaruni Nayak, Shafiq Joty, and Josip Car. In 2022 Machine Learning for Health (Proceedings Track) (ML4H@NeurIPS'22) 2022.
PDF Abstract BibTex Slides
Towards Summary Candidates Fusion
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. In the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. In the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Learning Label Modular Prompts for Text Classification in the Wild
Hailin Chen, Amrita Saha, Shafiq Joty, and Steven Hoi. In the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP'22) 2022.
Abstract BibTex Slides
Hailin Chen, Amrita Saha, Shafiq Joty, and Steven Hoi. In the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP'22) 2022.
Abstract BibTex Slides

OpenCQA: Open-ended Question Answering with Charts
Shankar Kantharaj, Xuan Long, Rixie Tiffany, Jia Qing, Enamul Hoque, and Shafiq Joty. In the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Shankar Kantharaj, Xuan Long, Rixie Tiffany, Jia Qing, Enamul Hoque, and Shafiq Joty. In the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Enhancing Multilingual Language Model with Massive Multilingual Knowledge Triples
Linlin Liu, Xin Li, Ruidan He, Lidong Bing, Shafiq Joty, and Luo Si. In the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Linlin Liu, Xin Li, Ruidan He, Lidong Bing, Shafiq Joty, and Luo Si. In the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP'22) 2022.
PDF Abstract BibTex Slides

Alleviating Sparsity of Open Knowledge Graphs with Ternary Contrastive Learning
Qian Li, Shafiq Joty, Daling Wang, Shi Feng, and Yifei Zhang. In the 2022 Conference on Empirical Methods in Natural Language Processing (Findings) (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Qian Li, Shafiq Joty, Daling Wang, Shi Feng, and Yifei Zhang. In the 2022 Conference on Empirical Methods in Natural Language Processing (Findings) (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Data Selection Curriculum for Neural Machine Translation
Tasnim Mohiuddin, Philipp Koehn, Vishrav Chaudhary, James Cross, Shruti Bhosale, and Shafiq Joty. In the 2022 Conference on Empirical Methods in Natural Language Processing (Findings) (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Tasnim Mohiuddin, Philipp Koehn, Vishrav Chaudhary, James Cross, Shruti Bhosale, and Shafiq Joty. In the 2022 Conference on Empirical Methods in Natural Language Processing (Findings) (EMNLP'22) 2022.
PDF Abstract BibTex Slides
BotSIM: An End-to-End Bot Simulation Framework for Commercial Task-Oriented Dialog Systems
Guangsen Wang, Samson Tan, Shafiq Joty, Gang Wu, Jimmy Au, and Steven Hoi. In the 2022 Conference on Empirical Methods in Natural Language Processing (demo) (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Guangsen Wang, Samson Tan, Shafiq Joty, Gang Wu, Jimmy Au, and Steven Hoi. In the 2022 Conference on Empirical Methods in Natural Language Processing (demo) (EMNLP'22) 2022.
PDF Abstract BibTex Slides
Refining Low-Resource Unsupervised Translation by Language Disentanglement of Multilingual Translation Model
Xuan-Phi Nguyen, Shafiq Joty, Wu Kui, and Ai Ti. In 2022 Conference on Neural Information Processing Systems (NeurIPS'22) 2022.
PDF Abstract BibTex Slides
Xuan-Phi Nguyen, Shafiq Joty, Wu Kui, and Ai Ti. In 2022 Conference on Neural Information Processing Systems (NeurIPS'22) 2022.
PDF Abstract BibTex Slides

GradMask: Gradient-Guided Token Masking for Textual Adversarial Example Detection
Han-Cheol Moon, Shafiq Joty, and Xu Chi. In 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD'22) 2022.
PDF Abstract BibTex Slides
Han-Cheol Moon, Shafiq Joty, and Xu Chi. In 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD'22) 2022.
PDF Abstract BibTex Slides
Rethinking Self-Supervision Objectives for Generalizable Coherence Modeling
Prathyusha Jwalapuram, Shafiq Joty, and Xiang Lin. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides
Prathyusha Jwalapuram, Shafiq Joty, and Xiang Lin. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides
Continual Few-shot Relation Learning via Embedding Space Regularization and Data Augmentation
Chengwei Qin, and Shafiq Joty. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides
Chengwei Qin, and Shafiq Joty. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides
SummaReranker: A Multi-Task Mixture-of-Experts Re-Ranking Framework for Abstractive Summarization
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides

Chart-to-Text: A Large-Scale Benchmark for Chart Summarization
Shankar Kantharaj, Rixie Leong, Xiang Lin, Ahmed Masry, Megh Thakkar, Enamul Hoque, and Shafiq Joty. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides
Shankar Kantharaj, Rixie Leong, Xiang Lin, Ahmed Masry, Megh Thakkar, Enamul Hoque, and Shafiq Joty. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides

GlobalWoZ: Globalizing MultiWoZ to Develop Multilingual Task-Oriented Dialogue Systems
Bosheng Ding, Junjie Hu, Lidong Bing, Mahani Aljunied, Shafiq Joty, Luo Si, and Chunyan Miao. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides
Bosheng Ding, Junjie Hu, Lidong Bing, Mahani Aljunied, Shafiq Joty, Luo Si, and Chunyan Miao. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22) 2022.
PDF Abstract BibTex Slides

ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Ahmed Masry, Do Xuan, Jia Qing, Shafiq Joty, and Enamul Hoque. In Findings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22 Findings) 2022.
PDF Abstract BibTex Slides
Ahmed Masry, Do Xuan, Jia Qing, Shafiq Joty, and Enamul Hoque. In Findings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL'22 Findings) 2022.
PDF Abstract BibTex Slides

LFPT5: A Unified Framework for Lifelong Few-shot Language Learning Based on Prompt Tuning of T5
Chengwei Qin, and Shafiq Joty. In International Conference on Learning Representations (ICLR-22) 2022.
PDF Abstract BibTex Slides
Chengwei Qin, and Shafiq Joty. In International Conference on Learning Representations (ICLR-22) 2022.
PDF Abstract BibTex Slides
Contrastive Clustering to Mine Pseudo Parallel Data for Unsupervised Translation
Xuan-Phi Nguyen, Hongyu Gong, Yun Tang, Changhan Wang, Philipp Koehn, and Shafiq Joty. In International Conference on Learning Representations (ICLR-22) 2022.
PDF Abstract BibTex Slides
Xuan-Phi Nguyen, Hongyu Gong, Yun Tang, Changhan Wang, Philipp Koehn, and Shafiq Joty. In International Conference on Learning Representations (ICLR-22) 2022.
PDF Abstract BibTex Slides

Weakly Supervised Neuro-Symbolic Module Networks for Numerical Reasoning
Amrita Saha, Shafiq Joty, and Steven Hoi. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI'22) 2022.
PDF Abstract BibTex Slides
Amrita Saha, Shafiq Joty, and Steven Hoi. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI'22) 2022.
PDF Abstract BibTex Slides
CoHS-CQG: Context and History Selection for Conversational Question Generation
Xuan Long, Bowei Zou, Liangming Pan, Nancy Chen, Shafiq Joty, and Ai Ti. In Proceedings of the 29th International Conference on Computational Linguistics (COLING'22) , pages xx-xx, 2022.
PDF Abstract BibTex Slides
Xuan Long, Bowei Zou, Liangming Pan, Nancy Chen, Shafiq Joty, and Ai Ti. In Proceedings of the 29th International Conference on Computational Linguistics (COLING'22) , pages xx-xx, 2022.
PDF Abstract BibTex Slides
Towards Multi-Sense Cross-Lingual Alignment of Contextual Embeddings
Linlin Liu, Thien Hai, Shafiq Joty, Lidong Bing, and Luo Si. In Proceedings of the 29th International Conference on Computational Linguistics (COLING'22) , pages xx-xx, 2022.
PDF Abstract BibTex Slides
Linlin Liu, Thien Hai, Shafiq Joty, Lidong Bing, and Luo Si. In Proceedings of the 29th International Conference on Computational Linguistics (COLING'22) , pages xx-xx, 2022.
PDF Abstract BibTex Slides
Unsupervised Cross-lingual Image Captioning
Jiahui Gao, Yi Zhou, Philip Yu, Shafiq Joty, and Jiuxiang Gu. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI'22) 2022.
PDF Abstract BibTex Slides
Jiahui Gao, Yi Zhou, Philip Yu, Shafiq Joty, and Jiuxiang Gu. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI'22) 2022.
PDF Abstract BibTex Slides
LANTERN: Boredom-conscious Natural Language Description Generation of Query Execution Plans for Database Education
Peng Chen, Hui Li, Sourav Bhowmick, Shafiq Joty, and Weiguo Wang. In Proceedings of 2022 ACM SIGMOD International Conference on Management of Data (Demo) (SIGMOD'22 (Demo)) , pages x - x, 2022.
PDF Abstract BibTex Slides
Peng Chen, Hui Li, Sourav Bhowmick, Shafiq Joty, and Weiguo Wang. In Proceedings of 2022 ACM SIGMOD International Conference on Management of Data (Demo) (SIGMOD'22 (Demo)) , pages x - x, 2022.
PDF Abstract BibTex Slides
PIANO: Influence Maximization Meets Deep Reinforcement Learning
Hui Li, Mengting Xu, Sourav Bhowmick, Shafiq Joty, Changsheng Sun, and Jiangtao Cui. In IEEE Transactions on Computational Social Systems (IEEE TCSS) 2022.
PDF Abstract BibTex
Hui Li, Mengting Xu, Sourav Bhowmick, Shafiq Joty, Changsheng Sun, and Jiangtao Cui. In IEEE Transactions on Computational Social Systems (IEEE TCSS) 2022.
PDF Abstract BibTex

NLP4Vis: Natural Language Processing for Information Visualization
Shafiq Joty, and Enamul Hoque. In Proceedings of the 2022 IEEE Vis Conference (IEEE Vis'22) 2022.
PDF Abstract BibTex Slides
Shafiq Joty, and Enamul Hoque. In Proceedings of the 2022 IEEE Vis Conference (IEEE Vis'22) 2022.
PDF Abstract BibTex Slides
2021
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Junnan Li, Ramprasaath R., Akhilesh Deepak, Shafiq Joty, Caiming Xiong, and Steven Hoi. In 2021 Conference on Neural Information Processing Systems (NeurIPS'21 (spotlight ~3%)) 2021.
PDF Abstract BibTex Slides
Junnan Li, Ramprasaath R., Akhilesh Deepak, Shafiq Joty, Caiming Xiong, and Steven Hoi. In 2021 Conference on Neural Information Processing Systems (NeurIPS'21 (spotlight ~3%)) 2021.
PDF Abstract BibTex Slides

Straight to the Gradient: Learning to Use Novel Tokens for Neural Text Generation
Xiang Lin, Simeng Han, and Shafiq Joty. In Thirty-eighth International Conference on Machine Learning (ICML'21 (as long talk ~3%)) 2021.
PDF Abstract BibTex Slides
Xiang Lin, Simeng Han, and Shafiq Joty. In Thirty-eighth International Conference on Machine Learning (ICML'21 (as long talk ~3%)) 2021.
PDF Abstract BibTex Slides

Cross-model Back-translated Distillation for Unsupervised Machine Translation
Xuan-Phi Nguyen, Shafiq Joty, Thanh-Tung Nguyen, Wu Kui, and Ai Ti. In Thirty-eighth International Conference on Machine Learning (ICML'21) 2021.
PDF Abstract BibTex Slides
Xuan-Phi Nguyen, Shafiq Joty, Thanh-Tung Nguyen, Wu Kui, and Ai Ti. In Thirty-eighth International Conference on Machine Learning (ICML'21) 2021.
PDF Abstract BibTex Slides
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation
Yue Wang, Weishi Wang, Shafiq Joty, and Steven Hoi. In the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'21) 2021.
PDF Abstract BibTex Slides
Yue Wang, Weishi Wang, Shafiq Joty, and Steven Hoi. In the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'21) 2021.
PDF Abstract BibTex Slides
Effective Fine-tuning Methods for Cross-lingual Adaptation
Tao Yu, and Shafiq Joty. In the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'21) 2021.
PDF Abstract BibTex Slides
Tao Yu, and Shafiq Joty. In the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'21) 2021.
PDF Abstract BibTex Slides
A Unified Speaker Adaptation Approach for ASR
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'21) 2021.
PDF Abstract BibTex Slides
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'21) 2021.
PDF Abstract BibTex Slides
GeDi: Generative Discriminator Guided Sequence Generation
Ben Krause, Akhilesh Deepak, Bryan McCann, Nitish Shirish, Shafiq Joty, Richard Socher, and Nazneen Fatema. In the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'21 Findings) 2021.
PDF Abstract BibTex Slides
Ben Krause, Akhilesh Deepak, Bryan McCann, Nitish Shirish, Shafiq Joty, Richard Socher, and Nazneen Fatema. In the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP'21 Findings) 2021.
PDF Abstract BibTex Slides
UXLA: A Robust Unsupervised Data Augmentation Framework for Cross-Lingual NLP
M Saiful, Tasnim Mohiuddin, and Shafiq Joty. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21) , pages 1978–-1992, 2021.
Abstract BibTex Slides
M Saiful, Tasnim Mohiuddin, and Shafiq Joty. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21) , pages 1978–-1992, 2021.
Abstract BibTex Slides

A Conditional Splitting Framework for Efficient Constituency Parsing
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides

Reliability Testing for Natural Language Processing Systems
Samson Tan, Shafiq Joty, Kathy Baxter, Araz Taeihagh, Gregory A., and Min-Yen Kan. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21) , pages 4153–4169, 2021.
PDF Abstract BibTex Slides
Samson Tan, Shafiq Joty, Kathy Baxter, Araz Taeihagh, Gregory A., and Min-Yen Kan. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21) , pages 4153–4169, 2021.
PDF Abstract BibTex Slides
MulDA: A Multilingual Data Augmentation Framework for Low-Resource Cross-Lingual NER
Linlin Liu, Bosheng Ding, Lidong Bing, Shafiq Joty, Luo Si, and Chunyan Miao. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
Linlin Liu, Bosheng Ding, Lidong Bing, Shafiq Joty, Luo Si, and Chunyan Miao. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
AugVic: Exploiting BiText Vicinity for Low-Resource NMT
Tasnim Mohiuddin, M Saiful, and Shafiq Joty. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21 Findings) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
Tasnim Mohiuddin, M Saiful, and Shafiq Joty. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL'21 Findings) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
Code-Mixing on Sesame Street: Dawn of the Adversarial Polyglots
Samson Tan, and Shafiq Joty. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
Samson Tan, and Shafiq Joty. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides

RST Parsing from Scratch
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides

Improving Zero and Few-Shot Abstractive Summarization with Intermediate Fine-tuning and Data Augmentation
Alexander Fabbri, Simeng Han, Haoyuan Li, Haoran Li, Marjan Ghazvininejad, Shafiq Joty, Dragomir Radev, and Yashar Mehdad. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
Alexander Fabbri, Simeng Han, Haoyuan Li, Haoran Li, Marjan Ghazvininejad, Shafiq Joty, Dragomir Radev, and Yashar Mehdad. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'21) , pages xx–-xx, 2021.
PDF Abstract BibTex Slides
Addressing the Vulnerability of NMT in Input Perturbations
Weiwen Xu, AiTi Aw, Yang Ding, Kui Wu, and Shafiq Joty. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Industry Track) (NAACL'21) , pages xx–-xx, 2021.
Abstract BibTex Slides
Weiwen Xu, AiTi Aw, Yang Ding, Kui Wu, and Shafiq Joty. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Industry Track) (NAACL'21) , pages xx–-xx, 2021.
Abstract BibTex Slides

Rethinking Coherence Modeling: Synthetic vs. Downstream Tasks
Tasnim Mohiuddin*, Prathyusha Jwalapuram*, Xiang Lin*, and Shafiq Joty*. In Proceedings of the European Chapter of the ACL (EACL'21) , pages x–-x, 2021.
PDF Abstract BibTex Slides
Tasnim Mohiuddin*, Prathyusha Jwalapuram*, Xiang Lin*, and Shafiq Joty*. In Proceedings of the European Chapter of the ACL (EACL'21) , pages x–-x, 2021.
PDF Abstract BibTex Slides
Span-Level Emotion Cause Analysis by BERT-based Graph Attention Network
Xiangju Li, Wei Gao, Shi Feng, Wang Daling, and Shafiq Joty. In Proceedings of The 30th ACM International Conference on Information and Knowledge Management (CIKM'21 (short paper)) , pages xx-xx, 2021.
Abstract BibTex Slides
Xiangju Li, Wei Gao, Shi Feng, Wang Daling, and Shafiq Joty. In Proceedings of The 30th ACM International Conference on Information and Knowledge Management (CIKM'21 (short paper)) , pages xx-xx, 2021.
Abstract BibTex Slides

Span-level Emotion Cause Analysis with Neural Sequence Tagging
Xiangju Li, Wei Gao, Shi Feng, Wang Daling, and Shafiq Joty. In Proceedings of The 30th ACM International Conference on Information and Knowledge Management (CIKM'21 (short paper)) , pages xx-xx, 2021.
Abstract BibTex Slides
Xiangju Li, Wei Gao, Shi Feng, Wang Daling, and Shafiq Joty. In Proceedings of The 30th ACM International Conference on Information and Knowledge Management (CIKM'21 (short paper)) , pages xx-xx, 2021.
Abstract BibTex Slides

Preventing Early Endpointing for Online Automatic Speech Recognition
Yingzhu Zhao, Chongjia Ni, Cheung-Chi Leung, Shafiq Joty, Eng Siong, and Bin Ma. In International Conference on Acoustics, Speech, and Signal Processing (ICASSP'21) , pages xx - xx, 2021.
PDF Abstract BibTex Slides
Yingzhu Zhao, Chongjia Ni, Cheung-Chi Leung, Shafiq Joty, Eng Siong, and Bin Ma. In International Conference on Acoustics, Speech, and Signal Processing (ICASSP'21) , pages xx - xx, 2021.
PDF Abstract BibTex Slides

Towards Enhancing Database Education: Natural Language Generation Meets Query Execution Plans
Weiguo Wang, Sourav S, Hui Li, Shafiq Joty, and Siyuan Liu. In Proceedings of 2021 ACM SIGMOD International Conference on Management of Data (SIGMOD'21) , pages x - x, 2021.
Abstract BibTex Slides
Weiguo Wang, Sourav S, Hui Li, Shafiq Joty, and Siyuan Liu. In Proceedings of 2021 ACM SIGMOD International Conference on Management of Data (SIGMOD'21) , pages x - x, 2021.
Abstract BibTex Slides
2020

Data Diversification: An Elegant Strategy for Neural Machine Translation
Xuan-Phi Nguyen, Shafiq Joty, Wu Kui, and Ai Ti. In 2020 Conference on Neural Information Processing Systems (NeurIPS'20) 2020.
PDF Abstract BibTex Slides
Xuan-Phi Nguyen, Shafiq Joty, Wu Kui, and Ai Ti. In 2020 Conference on Neural Information Processing Systems (NeurIPS'20) 2020.
PDF Abstract BibTex Slides

Self-Supervised Relationship Probing
Jiuxiang Gu, Jason Kuen, Shafiq Joty, Jianfei Cai, Vlad Morariu, Handong Zhao, and Tong Sun. In 2020 Conference on Neural Information Processing Systems (NeurIPS'20) 2020.
PDF Abstract BibTex Slides
Jiuxiang Gu, Jason Kuen, Shafiq Joty, Jianfei Cai, Vlad Morariu, Handong Zhao, and Tong Sun. In 2020 Conference on Neural Information Processing Systems (NeurIPS'20) 2020.
PDF Abstract BibTex Slides
LNMap: Departures from Isomorphic Assumption in Bilingual Lexicon Induction Through Non-Linear Mapping in Latent Space
Tasnim Mohiuddin, M Saiful, and Shafiq Joty. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 2712–-2723, 2020.
PDF Abstract BibTex Slides
Tasnim Mohiuddin, M Saiful, and Shafiq Joty. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 2712–-2723, 2020.
PDF Abstract BibTex Slides

Pronoun-Targeted Finetuning for NMT with Hybrid Losses
Prathyusha Jwalapuram, Shafiq Joty, and Youlin Shen. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 2267–2279, 2020.
PDF Abstract BibTex Slides
Prathyusha Jwalapuram, Shafiq Joty, and Youlin Shen. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 2267–2279, 2020.
PDF Abstract BibTex Slides
Mind Your Inflections! Improving NLP for Non-Standard English with Base-Inflection Encoding
Samson Tan, Shafiq Joty, Lav R., and Min-Yen Kan. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 5647–-5663, 2020.
PDF Abstract BibTex Slides
Samson Tan, Shafiq Joty, Lav R., and Min-Yen Kan. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 5647–-5663, 2020.
PDF Abstract BibTex Slides
Response Selection for Multi-Party Conversations with Dynamic Topic Tracking
Weishi Wang, Shafiq Joty, and Steven Hoi. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 6581–-6591, 2020.
PDF Abstract BibTex Slides
Weishi Wang, Shafiq Joty, and Steven Hoi. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 6581–-6591, 2020.
PDF Abstract BibTex Slides

Online Conversation Disentanglement with Pointer Networks
Tao Yu, and Shafiq Joty. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 6321–-6330, 2020.
PDF Abstract BibTex Slides
Tao Yu, and Shafiq Joty. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 6321–-6330, 2020.
PDF Abstract BibTex Slides

VD-BERT: A Unified Vision and Dialog Transformer with BERT
Yue Wang, Shafiq Joty, Michael R., Irwin King, Caiming Xiong, and Steven Hoi. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 3325–-3338, 2020.
PDF Abstract BibTex Slides
Yue Wang, Shafiq Joty, Michael R., Irwin King, Caiming Xiong, and Steven Hoi. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 3325–-3338, 2020.
PDF Abstract BibTex Slides

Discern: Discourse-Aware Entailment Reasoning Network for Conversational Machine Reading
Yifan Gao, Chien-Sheng Wu, Jingjing Li, Shafiq Joty, Steven Hoi, Caiming Xiong, Irwin King, and Michael Lyu. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 2439–-2449, 2020.
PDF Abstract BibTex Slides
Yifan Gao, Chien-Sheng Wu, Jingjing Li, Shafiq Joty, Steven Hoi, Caiming Xiong, Irwin King, and Michael Lyu. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 2439–-2449, 2020.
PDF Abstract BibTex Slides

DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
Bosheng Ding, Linlin Liu, Lidong Bing, Canasai Kruengkrai, Thien Hai, Shafiq Joty, Luo Si, and Chunyan Miao. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 6045–-6057, 2020.
PDF Abstract BibTex Slides
Bosheng Ding, Linlin Liu, Lidong Bing, Canasai Kruengkrai, Thien Hai, Shafiq Joty, Luo Si, and Chunyan Miao. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 6045–-6057, 2020.
PDF Abstract BibTex Slides

Workshop on Simple and Efficient Natural Language Processing
Nafise Sadat Moosavi, Angela Fan, Vered Shwartz, Goran Glavas, Shafiq Joty, Alex Wang, and Thomas Wolf. In Proceedings of SustaiNLP (EMNLP'20 Workshop) 2020.
PDF BibTex Slides
Nafise Sadat Moosavi, Angela Fan, Vered Shwartz, Goran Glavas, Shafiq Joty, Alex Wang, and Thomas Wolf. In Proceedings of SustaiNLP (EMNLP'20 Workshop) 2020.
PDF BibTex Slides

Efficient Constituency Parsing by Pointing
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL'20) , pages 3284–-3294, 2020.
PDF Abstract BibTex Slides
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL'20) , pages 3284–-3294, 2020.
PDF Abstract BibTex Slides

Differentiable Window for Dynamic Local Attention
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL'20) , pages 6589–-6599, 2020.
PDF Abstract BibTex Slides
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL'20) , pages 6589–-6599, 2020.
PDF Abstract BibTex Slides

EMT: Explicit Memory Tracker with Coarse-to-Fine Reasoning for Conversational Machine Reading
Yifan Gao, Chien-Sheng Wu, Shafiq Joty, Caiming Xiong, Richard Socher, Irwin King, Michael Lyu, and Steven Hoi. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL'20) , pages 935–-945, 2020.
PDF Abstract BibTex Slides
Yifan Gao, Chien-Sheng Wu, Shafiq Joty, Caiming Xiong, Richard Socher, Irwin King, Michael Lyu, and Steven Hoi. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL'20) , pages 935–-945, 2020.
PDF Abstract BibTex Slides
It’s Morphin’ Time! Combating Linguistic Discrimination with Inflectional Perturbations
Samson Tan, Shafiq Joty, Min-Yen Kan, and Richard Socher. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL'20) , pages 2920–-2935, 2020.
PDF Abstract BibTex Slides
Samson Tan, Shafiq Joty, Min-Yen Kan, and Richard Socher. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL'20) , pages 2920–-2935, 2020.
PDF Abstract BibTex Slides

Tree-Structured Attention with Hierarchical Accumulation
Xuan-Phi Nguyen, Shafiq Joty, Steven Hoi, and Richard Socher. In International Conference on Learning Representations (ICLR-20) 2020.
PDF Abstract BibTex Slides
Xuan-Phi Nguyen, Shafiq Joty, Steven Hoi, and Richard Socher. In International Conference on Learning Representations (ICLR-20) 2020.
PDF Abstract BibTex Slides
Finding It at Another Side: A Viewpoint-Adapted Matching Encoder for Change Captioning
Xiangxi Shi, Xu Yang, Jiuxiang Gu, Shafiq Joty, and Jianfei Cai. In European Conference on Computer Vision (ECCV'20) 2020.
PDF Abstract BibTex Slides
Xiangxi Shi, Xu Yang, Jiuxiang Gu, Shafiq Joty, and Jianfei Cai. In European Conference on Computer Vision (ECCV'20) 2020.
PDF Abstract BibTex Slides
Zero-Resource Cross-Lingual Named Entity Recognition
Saiful Bari, Shafiq Joty, and Prathyusha Jwalapuram. In Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI'20) , pages 7415-7423, 2020.
PDF Abstract BibTex Slides
Saiful Bari, Shafiq Joty, and Prathyusha Jwalapuram. In Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI'20) , pages 7415-7423, 2020.
PDF Abstract BibTex Slides

Universal Speech Transformer
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In 21st Annual Conference of the International Speech Communication Association (Interspeech'20) , pages 5021 - 5025, 2020.
PDF Abstract BibTex Slides
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In 21st Annual Conference of the International Speech Communication Association (Interspeech'20) , pages 5021 - 5025, 2020.
PDF Abstract BibTex Slides
Speech Transformer with Speaker Aware Persistent Memory
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In 21st Annual Conference of the International Speech Communication Association (Interspeech'20) , pages 1261 - 1265, 2020.
PDF Abstract BibTex Slides
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In 21st Annual Conference of the International Speech Communication Association (Interspeech'20) , pages 1261 - 1265, 2020.
PDF Abstract BibTex Slides

Cross Attention with Monotonic Alignment for Speech Transformer
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In 21st Annual Conference of the International Speech Communication Association (Interspeech'20) , pages 5031 - 5035, 2020.
PDF Abstract BibTex Slides
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In 21st Annual Conference of the International Speech Communication Association (Interspeech'20) , pages 5031 - 5035, 2020.
PDF Abstract BibTex Slides
Unsupervised Word Translation with Adversarial Autoencoder
Tasnim Mohiuddin, and Shafiq Joty. In Computational Linguistics (presented at ACL-2020) : pages 1 - 32, 2020.
PDF Abstract BibTex
Tasnim Mohiuddin, and Shafiq Joty. In Computational Linguistics (presented at ACL-2020) : pages 1 - 32, 2020.
PDF Abstract BibTex
An Attention-based Rumor Detection Model with Tree-structured Recursive Neural Networks
Jing Ma, Wei Gao, Shafiq Joty, and Kam-Fai Wong. In ACM Transactions on Intelligent Systems and Technology (TIST) : pages 1-28, 2020.
PDF Abstract BibTex
Jing Ma, Wei Gao, Shafiq Joty, and Kam-Fai Wong. In ACM Transactions on Intelligent Systems and Technology (TIST) : pages 1-28, 2020.
PDF Abstract BibTex

Video Captioning with Boundary-Aware Hierarchical Language Decoding and Joint Video Prediction
Xiangxi Shi, Jianfei Cai, Jiuxiang Gu, and Shafiq Joty. In Neurocomputing : pages 347-356, 2020.
PDF Abstract BibTex
Xiangxi Shi, Jianfei Cai, Jiuxiang Gu, and Shafiq Joty. In Neurocomputing : pages 347-356, 2020.
PDF Abstract BibTex

Conversational agents in healthcare: a scoping review and conceptual analysis
Lorainne Car, Dhakshenya Dhinagaran, Bhone Kyaw, Tobias Kowatsch, Shafiq Joty, Yin Theng, and Rifat Atun. In Journal of Medical Internet Research (JMIR) 2020.
PDF Abstract BibTex
Lorainne Car, Dhakshenya Dhinagaran, Bhone Kyaw, Tobias Kowatsch, Shafiq Joty, Yin Theng, and Rifat Atun. In Journal of Medical Internet Research (JMIR) 2020.
PDF Abstract BibTex

Resurrecting Submodularity for Neural Text Generation
Simeng Han, Xiang Lin, and Shafiq Joty. In arXiv (* not peer reviewed) 2020.
PDF Abstract BibTex
Simeng Han, Xiang Lin, and Shafiq Joty. In arXiv (* not peer reviewed) 2020.
PDF Abstract BibTex

Can Your Context-Aware MT System Pass the DiP Benchmark Tests? : Evaluation Benchmarks for Discourse Phenomena in Machine Translation
Prathyusha Jwalapuram, Barbara Rychalska, Shafiq Joty, and Dominika Basaj. In arXiv (* not peer reviewed) 2020.
PDF Abstract BibTex
Prathyusha Jwalapuram, Barbara Rychalska, Shafiq Joty, and Dominika Basaj. In arXiv (* not peer reviewed) 2020.
PDF Abstract BibTex
2019

Hierarchical Pointer Net Parsing
Linlin Liu*, Xiang Lin*, Shafiq Joty, Simeng Han, and Lidong Bing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP'19) , pages 1007–-1017, 2019.
PDF Abstract BibTex Slides
Linlin Liu*, Xiang Lin*, Shafiq Joty, Simeng Han, and Lidong Bing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP'19) , pages 1007–-1017, 2019.
PDF Abstract BibTex Slides

A Unified Neural Coherence Model
Han-Cheol Moon*, Tasnim Mohiuddin*, Shafiq Joty*, and Chi Xu. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP'19) , pages 2262–2272, 2019.
PDF Abstract BibTex Slides
Han-Cheol Moon*, Tasnim Mohiuddin*, Shafiq Joty*, and Chi Xu. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP'19) , pages 2262–2272, 2019.
PDF Abstract BibTex Slides
Evaluating Pronominal Anaphora in Machine Translation: An Evaluation Measure and a Test Suite
Prathyusha Jwalapuram, Shafiq Joty, Irina Temnikova, and Preslav Nakov. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP'19) , pages 2964–2975, 2019.
PDF Abstract BibTex Slides
Prathyusha Jwalapuram, Shafiq Joty, Irina Temnikova, and Preslav Nakov. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP'19) , pages 2964–2975, 2019.
PDF Abstract BibTex Slides

Using Clinical Notes with Multimodal Learning for ICU Management
Swaraj Khadanga, Karan Aggarwal, Shafiq Joty, and Jaideep Srivastava. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP'19) , pages 6432–6437, 2019.
PDF Abstract BibTex Slides
Swaraj Khadanga, Karan Aggarwal, Shafiq Joty, and Jaideep Srivastava. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP'19) , pages 6432–6437, 2019.
PDF Abstract BibTex Slides

A Unified Linear-Time Framework for Sentence-Level Discourse Parsing
Xiang Lin*, Shafiq Joty*, Prathyusha Jwalapuram, and Saiful Bari. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'19) , pages 4190–4200, 2019.
PDF Abstract BibTex Slides
Xiang Lin*, Shafiq Joty*, Prathyusha Jwalapuram, and Saiful Bari. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'19) , pages 4190–4200, 2019.
PDF Abstract BibTex Slides

Sentence-Level Evidence Embedding for End-to-End Claim Verification with Hierarchical Attention Networks
Jing Ma, Wei Gao, Shafiq Joty, and Kam-Fai Wong. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'19) , pages 2561–2571, 2019.
PDF Abstract BibTex Slides
Jing Ma, Wei Gao, Shafiq Joty, and Kam-Fai Wong. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'19) , pages 2561–2571, 2019.
PDF Abstract BibTex Slides

Discourse Processing and Its Applications
Shafiq Joty*, Giuseppe Carenini*, Raymond Ng, and Gabriel Murray. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts (ACL'19) , pages 1-6, 2019.
PDF Abstract BibTex Slides
Shafiq Joty*, Giuseppe Carenini*, Raymond Ng, and Gabriel Murray. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts (ACL'19) , pages 1-6, 2019.
PDF Abstract BibTex Slides
Unpaired Image Captioning via Scene Graph Alignments
Jiuxiang Gu, Shafiq Joty, Jianfei Cai, Handong Zhao, Xu Yang, and Gang Wang. In Proceedings of the International Conference on Computer Vision (ICCV'19) , pages 10323-10332, 2019.
PDF Abstract BibTex Slides
Jiuxiang Gu, Shafiq Joty, Jianfei Cai, Handong Zhao, Xu Yang, and Gang Wang. In Proceedings of the International Conference on Computer Vision (ICCV'19) , pages 10323-10332, 2019.
PDF Abstract BibTex Slides

Watch It Twice: Video Captioning with a Refocused Video Encoder
Xiangxi Shi, Jianfei Cai, Shafiq Joty, and Jiuxiang Gu. In Proceedings of the 27th ACM International Conference on Multimedia (ACMMM'19) , pages 818–826, 2019.
PDF Abstract BibTex Slides
Xiangxi Shi, Jianfei Cai, Shafiq Joty, and Jiuxiang Gu. In Proceedings of the 27th ACM International Conference on Multimedia (ACMMM'19) , pages 818–826, 2019.
PDF Abstract BibTex Slides
Revisiting Adversarial Autoencoder for Unsupervised Word Translation with Cycle Consistency and Improved Training
Tasnim Mohiuddin, and Shafiq Joty. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'19) , pages 3857–3867, 2019.
PDF Abstract BibTex Slides
Tasnim Mohiuddin, and Shafiq Joty. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'19) , pages 3857–3867, 2019.
PDF Abstract BibTex Slides
Adaptation of Hierarchical Structured Models for Speech Act Recognition in Asynchronous Conversation
Tasnim Mohiuddin*, Thanh-Tung Nguyen*, and Shafiq Joty*. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'19) , pages 1326–1336, 2019.
PDF Abstract BibTex Slides
Tasnim Mohiuddin*, Thanh-Tung Nguyen*, and Shafiq Joty*. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'19) , pages 1326–1336, 2019.
PDF Abstract BibTex Slides
Adversarial Unsupervised Representation Learning for Activity Time-Series
Karan Aggarwal, Shafiq Joty, Luis Fernandez-Luque, and Jaideep Srivastava. In Thirty-Third AAAI Conference on Artificial Intelligence (AAAI'19) , pages 834 - 841, 2019.
PDF Abstract BibTex Slides
Karan Aggarwal, Shafiq Joty, Luis Fernandez-Luque, and Jaideep Srivastava. In Thirty-Third AAAI Conference on Artificial Intelligence (AAAI'19) , pages 834 - 841, 2019.
PDF Abstract BibTex Slides
A Fatorial Deep Markov Model For Unsupervised Disentangled Representation Learning From Speech
Sameer Khurana, Shafiq Joty, Ahmed Ali, and James Glass. In International Conference on Acoustics, Speech, and Signal Processing (ICASSP'19) , pages 6540 - 6544, 2019.
PDF Abstract BibTex Slides
Sameer Khurana, Shafiq Joty, Ahmed Ali, and James Glass. In International Conference on Acoustics, Speech, and Signal Processing (ICASSP'19) , pages 6540 - 6544, 2019.
PDF Abstract BibTex Slides
NEURON: Query Execution Plan Meets Natural Language Processing For Augmenting DB Education
Siyuan Liu, Sourav S, Wanlu Zhang, Shu Wang, Wanyi Huang, and Shafiq Joty. In Proceedings of 45th ACM SIGMOD International Conference on Management of Data (Demo) (SIGMOD'19 (Demo)) , pages 1953–1956, 2019.
PDF Abstract BibTex Slides
Siyuan Liu, Sourav S, Wanlu Zhang, Shu Wang, Wanyi Huang, and Shafiq Joty. In Proceedings of 45th ACM SIGMOD International Conference on Management of Data (Demo) (SIGMOD'19 (Demo)) , pages 1953–1956, 2019.
PDF Abstract BibTex Slides
2018
Phrase-Based Attentions
Phi Xuan, and Shafiq Joty. In arXiv (* not peer reviewed) 2018.
PDF Abstract BibTex
Phi Xuan, and Shafiq Joty. In arXiv (* not peer reviewed) 2018.
PDF Abstract BibTex
Speech Act Modeling of Written Asynchronous Conversations: A Neural CRF Approach
Shafiq Joty, and Tasnim Mohiuddin. In Computational Linguistics (Special Issue on Language in Social Media, Exploiting discourse and other contextual information) : pages 859 - 894, 2018.
PDF Abstract BibTex
Shafiq Joty, and Tasnim Mohiuddin. In Computational Linguistics (Special Issue on Language in Social Media, Exploiting discourse and other contextual information) : pages 859 - 894, 2018.
PDF Abstract BibTex
Joint Multitask Learning for Community Question Answering Using Task-Specific Embeddings
Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP'18) , pages 4196 - 4207, 2018.
PDF Abstract BibTex Slides
Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP'18) , pages 4196 - 4207, 2018.
PDF Abstract BibTex Slides
Coherence Modeling of Asynchronous Conversations: A Neural Entity Grid Approach
Shafiq Joty*, Tasnim Mohiuddin*, and Dat Nguyen*. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'18) , pages 558–-568, 2018.
PDF Abstract BibTex Slides
Shafiq Joty*, Tasnim Mohiuddin*, and Dat Nguyen*. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'18) , pages 558–-568, 2018.
PDF Abstract BibTex Slides
Domain Adaptation with Adversarial Training and Graph Embeddings
Firoj Alam, Shafiq Joty, and Muhammad Imran. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'18) , pages 1077–-1087, 2018.
PDF Abstract BibTex Slides
Firoj Alam, Shafiq Joty, and Muhammad Imran. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'18) , pages 1077–-1087, 2018.
PDF Abstract BibTex Slides
Unpaired Image Captioning by Language Pivoting
Jiuxiang Gu, Shafiq Joty, Jianfei Cai, and Gang Wang. In European Conference on Computer Vision (ECCV'18) , pages xx-xx, 2018.
PDF Abstract BibTex Slides
Jiuxiang Gu, Shafiq Joty, Jianfei Cai, and Gang Wang. In European Conference on Computer Vision (ECCV'18) , pages xx-xx, 2018.
PDF Abstract BibTex Slides
VQA-E: Explaining, Elaborating, and Enhancing Your Answers for Visual Questions
Qing Li, Qingyi Tao, Shafiq Joty, Jianfei Cai, and Jiebo Luo. In European Conference on Computer Vision (ECCV'18) , pages xx-xx, 2018.
PDF Abstract BibTex Slides
Qing Li, Qingyi Tao, Shafiq Joty, Jianfei Cai, and Jiebo Luo. In European Conference on Computer Vision (ECCV'18) , pages xx-xx, 2018.
PDF Abstract BibTex Slides
Look, Imagine and Match: Improving Textual-Visual Cross-Modal Retrieval with Generative Models
Jiuxiang Gu, Jianfei Cai, Shafiq Joty, Li Niu, and Gang Wang. In Computer Vision and Pattern Recognition (CVPR'18, Spotlight) , pages xx-xx, 2018.
PDF Abstract BibTex Slides
Jiuxiang Gu, Jianfei Cai, Shafiq Joty, Li Niu, and Gang Wang. In Computer Vision and Pattern Recognition (CVPR'18, Spotlight) , pages xx-xx, 2018.
PDF Abstract BibTex Slides
Aspect-based Neural Recommender
Chin Yao, Kaiqi Zhao, Shafiq Joty, and Gao Cong. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM'18) , pages 147 - 156, 2018.
PDF Abstract BibTex Slides
Chin Yao, Kaiqi Zhao, Shafiq Joty, and Gao Cong. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM'18) , pages 147 - 156, 2018.
PDF Abstract BibTex Slides

SegBot: A Generic Neural Text Segmentation Model with Pointer Network
Jing Li, Aixin Sun, and Shafiq Joty. In Proceedings of the 27th International Joint Conference on Artificial Intelligence and the 23rd European Conference on Artificial Intelligence (IJCAI-ECAI-2018) , pages 4166 - 4172, 2018.
PDF Abstract BibTex Slides
Jing Li, Aixin Sun, and Shafiq Joty. In Proceedings of the 27th International Joint Conference on Artificial Intelligence and the 23rd European Conference on Artificial Intelligence (IJCAI-ECAI-2018) , pages 4166 - 4172, 2018.
PDF Abstract BibTex Slides
A Structured Learning Approach with Neural Conditional Random Fields for Sleep Staging
Karan Aggarwal, Swaraj Khadanga, Shafiq Joty, Louis Kazaglis, and Jaideep Srivastava. In IEEE Big Data 2018 2018.
PDF Abstract BibTex Slides
Karan Aggarwal, Swaraj Khadanga, Shafiq Joty, Louis Kazaglis, and Jaideep Srivastava. In IEEE Big Data 2018 2018.
PDF Abstract BibTex Slides
Distributed Representations of Tuples for Entity Resolution
Muhammad Ebraheem, Saravanan Thirumuruganathan, Shafiq Joty, Mourad Ouzzani, and Nan Tang. In The Forty-fourth International Conference on Very Large Data Bases (VLDB-2018) , pages 1454 - 1467, 2018.
PDF Abstract BibTex Slides
Muhammad Ebraheem, Saravanan Thirumuruganathan, Shafiq Joty, Mourad Ouzzani, and Nan Tang. In The Forty-fourth International Conference on Very Large Data Bases (VLDB-2018) , pages 1454 - 1467, 2018.
PDF Abstract BibTex Slides

NLP for Conversations: Sentiment, Summarization, and Group Dynamics
Gabriel Murray*, Shafiq Joty*, and Giuseppe Carenini*. In Proceedings of the 27th International Conference on Computational Linguistics: Tutorial Abstracts (COLING'18) , pages 1-4, 2018.
PDF Abstract BibTex Slides
Gabriel Murray*, Shafiq Joty*, and Giuseppe Carenini*. In Proceedings of the 27th International Conference on Computational Linguistics: Tutorial Abstracts (COLING'18) , pages 1-4, 2018.
PDF Abstract BibTex Slides

Discourse Processing and Its Applications in Text Mining
Shafiq Joty, Giuseppe Carenini, Raymond Ng, and Gabriel Murray. In IEEE International Conference on Data Mining: Tutorial Abstracts (ICDM'18) , pages 1-2, 2018.
PDF Abstract BibTex Slides
Shafiq Joty, Giuseppe Carenini, Raymond Ng, and Gabriel Murray. In IEEE International Conference on Data Mining: Tutorial Abstracts (ICDM'18) , pages 1-2, 2018.
PDF Abstract BibTex Slides
Graph Based Semi-supervised Learning with Convolutional Neural Networks to Classify Crisis Related Tweets
Firoj Alam, Shafiq Joty, and Muhammad Imran. In Proceedings of the Twelfth International Conference on Web and Social Media (ICWSM'18) , pages 556 - 559, 2018.
PDF Abstract BibTex Slides
Firoj Alam, Shafiq Joty, and Muhammad Imran. In Proceedings of the Twelfth International Conference on Web and Social Media (ICWSM'18) , pages 556 - 559, 2018.
PDF Abstract BibTex Slides
2017

Discourse Structure in Machine Translation Evaluation
Shafiq Joty, Francisco Guzmán, Lluís Màrquez, and Preslav Nakov. In Computational Linguistics : pages 683-722, 2017.
PDF Abstract BibTex
Shafiq Joty, Francisco Guzmán, Lluís Màrquez, and Preslav Nakov. In Computational Linguistics : pages 683-722, 2017.
PDF Abstract BibTex
Domain Adaptation Using Neural Network Joint Model
Shafiq Joty, Nadir Durrani, Hassan Sajjad, and Ahmed Abdelali. In Computer Speech & Language (Special Issue on Deep Learning for Machine Translation) : pages 161-179, 2017.
PDF Abstract BibTex
Shafiq Joty, Nadir Durrani, Hassan Sajjad, and Ahmed Abdelali. In Computer Speech & Language (Special Issue on Deep Learning for Machine Translation) : pages 161-179, 2017.
PDF Abstract BibTex
Machine translation evaluation with neural networks
Francisco Guzmán, Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Computer Speech & Language (Special Issue on Deep Learning for Machine Translation) : pages 180-200, 2017.
PDF Abstract BibTex
Francisco Guzmán, Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Computer Speech & Language (Special Issue on Deep Learning for Machine Translation) : pages 180-200, 2017.
PDF Abstract BibTex

A Neural Local Coherence Model
Dat Nguyen*, and Shafiq Joty*. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL'17) , pages 1320-1330, 2017.
PDF Abstract BibTex Slides
Dat Nguyen*, and Shafiq Joty*. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL'17) , pages 1320-1330, 2017.
PDF Abstract BibTex Slides
Cross-language Learning with Adversarial Neural Networks: Application to Community Question Answering
Shafiq Joty, Preslav Nakov, Lluís Màrquez, and Israa Jaradat. In Proceedings of The SIGNLL Conference on Computational Natural Language Learning (CoNLL'17) , pages 226-237, 2017.
PDF Abstract BibTex Slides
Shafiq Joty, Preslav Nakov, Lluís Màrquez, and Israa Jaradat. In Proceedings of The SIGNLL Conference on Computational Natural Language Learning (CoNLL'17) , pages 226-237, 2017.
PDF Abstract BibTex Slides
CON-S2V: A Generic Framework for Incorporating Extra-Sentential Context into Sen2Vec
Tanay Saha, Shafiq Joty, and Mohammad Hasan. In Proceedings of The European Conference on Machine Learning & Principles and Practice of knowledge discovery in databases (ECML-PKDD'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
Tanay Saha, Shafiq Joty, and Mohammad Hasan. In Proceedings of The European Conference on Machine Learning & Principles and Practice of knowledge discovery in databases (ECML-PKDD'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
Regularized and Retrofitted models for Learning Sentence Representation with Context
Tanay Saha, Shafiq Joty, Naeemul Hassan, and Mohammad Hasan. In Proceedings of the 26th ACM International Conference on Information and Knowledge Management (CIKM'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
Tanay Saha, Shafiq Joty, Naeemul Hassan, and Mohammad Hasan. In Proceedings of the 26th ACM International Conference on Information and Knowledge Management (CIKM'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
Cross-Language Question Re-ranking
Giovanni Da, Salvatore Romeo, Alberto Barron-Cedeno, Shafiq Joty, Lluís Màrquez, Alessandro Moschitti, and Preslav Nakov. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR'17) , pages 1145-1148, 2017.
PDF Abstract BibTex Slides
Giovanni Da, Salvatore Romeo, Alberto Barron-Cedeno, Shafiq Joty, Lluís Màrquez, Alessandro Moschitti, and Preslav Nakov. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR'17) , pages 1145-1148, 2017.
PDF Abstract BibTex Slides
Robust Classification of Crisis-Related Data on Social Networks Using Convolutional Neural Networks
Dat Nguyen, Kamela Ali, Shafiq Joty, Hassan Sajjad, Muhammad Imran, and Prasenjit Mitra. In Proceedings of the Eleventh International Conference on Web and Social Media (ICWSM'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
Dat Nguyen, Kamela Ali, Shafiq Joty, Hassan Sajjad, Muhammad Imran, and Prasenjit Mitra. In Proceedings of the Eleventh International Conference on Web and Social Media (ICWSM'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
CQAVis: Visual Text Analytics for Community Question Answering
Enamul Hoque, Shafiq Joty, Lluís Màrquez, and Giuseppe Carenini. In Proceedings of the 2017 international conference on Intelligent user interfaces (IUI'17) , pages 161-172, 2017.
PDF Abstract BibTex Slides
Enamul Hoque, Shafiq Joty, Lluís Màrquez, and Giuseppe Carenini. In Proceedings of the 2017 international conference on Intelligent user interfaces (IUI'17) , pages 161-172, 2017.
PDF Abstract BibTex Slides

Thread Reconstruction in Conversational Data using Neural Coherence Models
Dat Nguyen, Shafiq Joty, Basma Boussaha, and Maarten Rijke. In Proceedings of the Neu-IR 2017 SIGIR Workshop on Neural Information Retrieval (NeuIR'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
Dat Nguyen, Shafiq Joty, Basma Boussaha, and Maarten Rijke. In Proceedings of the Neu-IR 2017 SIGIR Workshop on Neural Information Retrieval (NeuIR'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
2016
Sleep Quality Prediction From Wearable Data Using Deep Learning
Aarti Sathyanarayana, Shafiq Joty, Luis Fernandez-Luque, Ferda Ofli, Jaideep Srivastava, Ahmed Elmagarmid, Shahrad Taheri, and Teresa Arora. In JMIR mHealth and uHealth (JMU) 2016.
PDF Abstract BibTex
Aarti Sathyanarayana, Shafiq Joty, Luis Fernandez-Luque, Ferda Ofli, Jaideep Srivastava, Ahmed Elmagarmid, Shahrad Taheri, and Teresa Arora. In JMIR mHealth and uHealth (JMU) 2016.
PDF Abstract BibTex

Speech Act Modeling of Written Asynchronous Conversations with Task-Specific Embeddings and Conditional Structured Models
Shafiq Joty, and Enamul Hoque. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL'16) , pages 1746-1756, 2016.
PDF Abstract BibTex Slides
Shafiq Joty, and Enamul Hoque. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL'16) , pages 1746-1756, 2016.
PDF Abstract BibTex Slides
Joint Learning with Global Inference for Comment Classification in Community Question Answering
Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'16) , pages 703–-713, 2016.
PDF Abstract BibTex Slides
Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'16) , pages 703–-713, 2016.
PDF Abstract BibTex Slides
A Deep Fusion Model for Domain Adaptation in Phrase-based MT
Nadir Durrani, Hassan Sajjad, Shafiq Joty, and Ahmed Abdelali. In Proceedings of the 26th International Conference on Computational Linguistics (COLING'16) , pages 3177-3187, 2016.
PDF Abstract BibTex Slides
Nadir Durrani, Hassan Sajjad, Shafiq Joty, and Ahmed Abdelali. In Proceedings of the 26th International Conference on Computational Linguistics (COLING'16) , pages 3177-3187, 2016.
PDF Abstract BibTex Slides
An Interactive System for Exploring Community Question Answering Forums
Enamul Hoque, Shafiq Joty, Lluís Màrquez, Alberto Barron-Cedeno, Giovanni Da San Martino, Alessandro Moschitti, Preslav Nakov, Salvatore Romeo, and Giuseppe Carenini. In Proceedings of the 26th International Conference on Computational Linguistics: System Demonstrations (COLING'16) , pages 1-5, 2016.
PDF Abstract BibTex Slides
Enamul Hoque, Shafiq Joty, Lluís Màrquez, Alberto Barron-Cedeno, Giovanni Da San Martino, Alessandro Moschitti, Preslav Nakov, Salvatore Romeo, and Giuseppe Carenini. In Proceedings of the 26th International Conference on Computational Linguistics: System Demonstrations (COLING'16) , pages 1-5, 2016.
PDF Abstract BibTex Slides

ConvKN at SemEval-2016 Task 3: Answer and Question Selection for Question Answering on Arabic and English Fora
Alberto Barron-Codeno, Giovanni Da San Martino, Shafiq Joty, Alessandro Moschitti, Fahad Al-Obaidli, Salvatore Romeo, Kateryna Tymoshenko, and Antonio Uva. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016) , pages 896-903, 2016.
PDF Abstract BibTex Slides
Alberto Barron-Codeno, Giovanni Da San Martino, Shafiq Joty, Alessandro Moschitti, Fahad Al-Obaidli, Salvatore Romeo, Kateryna Tymoshenko, and Antonio Uva. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016) , pages 896-903, 2016.
PDF Abstract BibTex Slides
Applications of Online Deep Learning for Crisis Response Using Social Media Information
Dat Tien, Shafiq Joty, Muhammad Imran, Hassan Sajjad, and Prasenjit Mitra. In 4th international workshop on Social Web for Disaster Management (SWDM'16) 2016.
PDF Abstract BibTex Slides
Dat Tien, Shafiq Joty, Muhammad Imran, Hassan Sajjad, and Prasenjit Mitra. In 4th international workshop on Social Web for Disaster Management (SWDM'16) 2016.
PDF Abstract BibTex Slides
2015

CODRA: A Novel Discriminative Framework for Rhetorical Analysis
Shafiq Joty, Giuseppe Carenini, and Raymond T Ng. In Computational Linguistics : pages 385-435, 2015.
PDF Abstract BibTex
Shafiq Joty, Giuseppe Carenini, and Raymond T Ng. In Computational Linguistics : pages 385-435, 2015.
PDF Abstract BibTex
Pairwise Neural Machine Translation Evaluation
Francisco Guzmán, Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and The 7th International Joint Conference of the Asian Federation of Natural Language Processing (ACL'15) , pages 805-814, 2015.
PDF Abstract BibTex Slides
Francisco Guzmán, Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and The 7th International Joint Conference of the Asian Federation of Natural Language Processing (ACL'15) , pages 805-814, 2015.
PDF Abstract BibTex Slides

Thread-Level Information for Comment Classification in Community Question Answering
Alberto Barron-Cedeno, Simone Filice, Giovanni Da San Martino, Shafiq Joty, Lluís Màrquez, Preslav Nakov, and Alessandro Moschitti. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL'15) , pages 687-693, 2015.
PDF Abstract BibTex Slides
Alberto Barron-Cedeno, Simone Filice, Giovanni Da San Martino, Shafiq Joty, Lluís Màrquez, Preslav Nakov, and Alessandro Moschitti. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL'15) , pages 687-693, 2015.
PDF Abstract BibTex Slides
Using Joint Models for Domain Adaptation in Statistical Machine Translation
Nadir Durrani, Hassan Sajjad, Shafiq Joty, Ahmed Abdelali, and Stephan Vogel. In Proceedings of the Association for Machine Translation in the Americas (AMTA'15) , pages 687-693, 2015.
PDF Abstract BibTex Slides
Nadir Durrani, Hassan Sajjad, Shafiq Joty, Ahmed Abdelali, and Stephan Vogel. In Proceedings of the Association for Machine Translation in the Americas (AMTA'15) , pages 687-693, 2015.
PDF Abstract BibTex Slides
How to Avoid Unwanted Pregnancies: Domain Adaptation using Neural Network Models
Shafiq Joty, Hassan Sajjad, Nadir Durrani, Kamla Al-Mannai, Ahmed Abdelali, and Stephan Vogel. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP'15) , pages 1259-1270, 2015.
PDF Abstract BibTex Slides
Shafiq Joty, Hassan Sajjad, Nadir Durrani, Kamla Al-Mannai, Ahmed Abdelali, and Stephan Vogel. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP'15) , pages 1259-1270, 2015.
PDF Abstract BibTex Slides
Fine-grained Opinion Mining with Recurrent Neural Networks and Word Embeddings
Pengfei Liu, Shafiq Joty, and Helen Meng. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP'15) , pages 1433-1443, 2015.
PDF Abstract BibTex Slides
Pengfei Liu, Shafiq Joty, and Helen Meng. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP'15) , pages 1433-1443, 2015.
PDF Abstract BibTex Slides
Global Thread-level Inference for Comment Classification in Community Question Answering
Shafiq Joty, Alberto Barron-Cedeno, Giovanni Da San Martino, Simone Filice, Lluís Màrquez, Alessandro Moschitti, and Preslav Nakov. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages 573-578, 2015.
PDF Abstract BibTex Slides
Shafiq Joty, Alberto Barron-Cedeno, Giovanni Da San Martino, Simone Filice, Lluís Màrquez, Alessandro Moschitti, and Preslav Nakov. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages 573-578, 2015.
PDF Abstract BibTex Slides
QCRI: Answer Selection for Community Question Answering - Experiments for Arabic and English
Massimo Nicosia, Simone Filice, Alberto Barron-Cedeno, Iman Saleh, Hamdy Mubarak, Wei Gao, Preslav Nakov, Giovanni Da, Alessandro Moschitti, Kareem Darwish, Llu\is Màrquez, Shafiq R., and Walid Magdy. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval'15) , pages 203-209, 2015.
PDF Abstract BibTex Slides
Massimo Nicosia, Simone Filice, Alberto Barron-Cedeno, Iman Saleh, Hamdy Mubarak, Wei Gao, Preslav Nakov, Giovanni Da, Alessandro Moschitti, Kareem Darwish, Llu\is Màrquez, Shafiq R., and Walid Magdy. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval'15) , pages 203-209, 2015.
PDF Abstract BibTex Slides
2014

Using Discourse Structure Improves Machine Translation Evaluation
Francisco Guzmán, Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL'14) , pages 687-698, 2014.
PDF Abstract BibTex Slides
Francisco Guzmán, Shafiq Joty, Lluís Màrquez, and Preslav Nakov. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL'14) , pages 687-698, 2014.
PDF Abstract BibTex Slides

Learning to Differentiate Better from Worse Translations
Francisco Guzmán, Shafiq Joty, Lluís Màrquez, Alessandro Moschitti, Preslav Nakov, and Massimo Nicosia. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP'14) , pages 214-220, 2014.
PDF Abstract BibTex Slides
Francisco Guzmán, Shafiq Joty, Lluís Màrquez, Alessandro Moschitti, Preslav Nakov, and Massimo Nicosia. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP'14) , pages 214-220, 2014.
PDF Abstract BibTex Slides

DiscoTK: Using Discourse Structure for Machine Translation Evaluation
Shafiq Joty, Francisco Guzmán, Lluís Màrquez, and Preslav Nakov. In Proceedings of the Ninth Workshop on Statistical Machine Translation (WMT'14) , pages 402-408, 2014.
PDF Abstract BibTex Slides
Shafiq Joty, Francisco Guzmán, Lluís Màrquez, and Preslav Nakov. In Proceedings of the Ninth Workshop on Statistical Machine Translation (WMT'14) , pages 402-408, 2014.
PDF Abstract BibTex Slides

Interactive Exploration of Asynchronous Conversations: Applying a User-centered Approach to Design a Visual Text Analytic System
Enamul Hoque, Giuseppe Carenini, and Shafiq Joty. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces (ILLVI'14) , pages 45-52, 2014.
PDF Abstract BibTex Slides
Enamul Hoque, Giuseppe Carenini, and Shafiq Joty. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces (ILLVI'14) , pages 45-52, 2014.
PDF Abstract BibTex Slides

Discriminative Reranking of Discourse Parses Using Tree Kernels
Shafiq Joty, and Alessandro Moschitti. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP'14) , pages 2049-2060, 2014.
PDF Abstract BibTex Slides
Shafiq Joty, and Alessandro Moschitti. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP'14) , pages 2049-2060, 2014.
PDF Abstract BibTex Slides

Semantic Kernels for Semantic Parsing
Iman Saleh, Alessandro Moschitti, Preslav Nakov, Lluís Màrquez, and Shafiq Joty. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP'14) , pages 436-442, 2014.
PDF Abstract BibTex Slides
Iman Saleh, Alessandro Moschitti, Preslav Nakov, Lluís Màrquez, and Shafiq Joty. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP'14) , pages 436-442, 2014.
PDF Abstract BibTex Slides

A Study of using Syntactic and Semantic Structures for Concept Segmentation and Labeling
Iman Saleh, Scott Cyphers, Jim Glass, Shafiq Joty, Lluís Màrquez, Alessandro Moschitti, and Preslav Nakov. In Proceedings of the 25th International Conference on Computational Linguistics: Technical Papers (COLING'14) , pages 193-202, 2014.
PDF Abstract BibTex Slides
Iman Saleh, Scott Cyphers, Jim Glass, Shafiq Joty, Lluís Màrquez, Alessandro Moschitti, and Preslav Nakov. In Proceedings of the 25th International Conference on Computational Linguistics: Technical Papers (COLING'14) , pages 193-202, 2014.
PDF Abstract BibTex Slides
2013
Topic Segmentation and Labeling in Asynchronous Conversations
Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In Journal of Artificial Intelligence Research : pages 521-573, 2013.
PDF Abstract BibTex
Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In Journal of Artificial Intelligence Research : pages 521-573, 2013.
PDF Abstract BibTex
Combining Intra- and Multi-sentential Rhetorical Parsing for Document-level Discourse Analysis
Shafiq Joty, Giuseppe Carenini, Raymond T. Ng, and Yashar Mehdad. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL'13) , pages 486-496, 2013.
PDF Abstract BibTex Slides
Shafiq Joty, Giuseppe Carenini, Raymond T. Ng, and Yashar Mehdad. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL'13) , pages 486-496, 2013.
PDF Abstract BibTex Slides
Towards Topic Labeling with Phrase Entailment and Aggregation
Yashar Mehdad, Giuseppe Carenini, Raymond T. Ng, and Shafiq Joty. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'13) , pages 179-189, 2013.
PDF Abstract BibTex Slides
Yashar Mehdad, Giuseppe Carenini, Raymond T. Ng, and Shafiq Joty. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL'13) , pages 179-189, 2013.
PDF Abstract BibTex Slides

Dialogue Act Recognition in Synchronous and Asynchronous Conversations
Maryam Tavafi, Yashar Mehdad, Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In Proceedings of the Special Interest Group on Discourse and Dialogue Conference (SIGDIAL'13) , pages 117-121, 2013.
PDF Abstract BibTex Slides
Maryam Tavafi, Yashar Mehdad, Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In Proceedings of the Special Interest Group on Discourse and Dialogue Conference (SIGDIAL'13) , pages 117-121, 2013.
PDF Abstract BibTex Slides
2012
A Novel Discriminative Framework for Sentence-Level Discourse Analysis
Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL'12) , pages 904-915, 2012.
PDF Abstract BibTex Slides
Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL'12) , pages 904-915, 2012.
PDF Abstract BibTex Slides

Automatic Topic Labeling in Asynchronous Conversations
Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In The Pacific Northwest Regional NLP Workshop (NWNLP'12) 2012.
PDF BibTex Slides
Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In The Pacific Northwest Regional NLP Workshop (NWNLP'12) 2012.
PDF BibTex Slides
Detecting Informative Blog Comments using Tree Structured Conditional Random Fields
Wei Jin, Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In The Pacific Northwest Regional NLP Workshop (NWNLP'12) 2012.
PDF BibTex Slides
Wei Jin, Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In The Pacific Northwest Regional NLP Workshop (NWNLP'12) 2012.
PDF BibTex Slides
2011
Improving Graph-based Random Walks for Complex Question Answering Using Syntactic, Shallow Semantic and Extended String Subsequence Kernels
Yllias Chali, Sadid Hasan, and Shafiq Joty. In Information Processing & Management : pages 843-855, 2011.
PDF Abstract BibTex
Yllias Chali, Sadid Hasan, and Shafiq Joty. In Information Processing & Management : pages 843-855, 2011.
PDF Abstract BibTex
Unsupervised Modeling of Dialog Acts in Asynchronous Conversations
Shafiq Joty, Giuseppe Carenini, and Chin-Yew Lin. In Proceedings of the twenty second International Joint Conference on Artificial Intelligence (IJCAI'11) , pages 1807-1813, 2011.
PDF Abstract BibTex Slides
Shafiq Joty, Giuseppe Carenini, and Chin-Yew Lin. In Proceedings of the twenty second International Joint Conference on Artificial Intelligence (IJCAI'11) , pages 1807-1813, 2011.
PDF Abstract BibTex Slides
Supervised Topic Segmentation of Email Conversations
Shafiq Joty, Giuseppe Carenini, Gabriel Murray, and Raymod Ng. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media (ICWSM'11) , pages 530-533, 2011.
PDF Abstract BibTex Slides
Shafiq Joty, Giuseppe Carenini, Gabriel Murray, and Raymod Ng. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media (ICWSM'11) , pages 530-533, 2011.
PDF Abstract BibTex Slides

Exploiting Conversational Features to Detect High-Quality Blog Comments
Nicholas FitzGerald, Giuseppe Carenini, Gabriel Murray, and Shafiq Joty. In Advances in Artificial Intelligence - 24th Canadian Conference on Artificial Intelligence Proceedings (CAI'11) , pages 122-127, 2011.
PDF Abstract BibTex Slides
Nicholas FitzGerald, Giuseppe Carenini, Gabriel Murray, and Shafiq Joty. In Advances in Artificial Intelligence - 24th Canadian Conference on Artificial Intelligence Proceedings (CAI'11) , pages 122-127, 2011.
PDF Abstract BibTex Slides
2010
Exploiting Conversation Structure in Unsupervised Topic Segmentation for Emails
Shafiq Joty, Giuseppe Carenini, Gabriel Murray, and Raymond Ng. In Proceedings of the conference on Empirical Methods in Natural Language Processing (EMNLP'10) , pages 388-398, 2010.
PDF Abstract BibTex Slides
Shafiq Joty, Giuseppe Carenini, Gabriel Murray, and Raymond Ng. In Proceedings of the conference on Empirical Methods in Natural Language Processing (EMNLP'10) , pages 388-398, 2010.
PDF Abstract BibTex Slides
Exploiting Conversation Features for Finding Topics in Emails
Shafiq Joty, Giuseppe Carenini, Gabriel Murray, and Raymond Ng. In The Pacific Northwest Regional NLP Workshop (NWNLP'10) 2010.
PDF Abstract BibTex Slides
Shafiq Joty, Giuseppe Carenini, Gabriel Murray, and Raymond Ng. In The Pacific Northwest Regional NLP Workshop (NWNLP'10) 2010.
PDF Abstract BibTex Slides
2009
Complex Question Answering: Unsupervised Learning Approaches and Experiments
Yllias Chali*, Shafiq Joty*, and Sadid Hasan*. In Journal of Artificial Intelligence Research : pages 1-47, 2009.
PDF Abstract BibTex
Yllias Chali*, Shafiq Joty*, and Sadid Hasan*. In Journal of Artificial Intelligence Research : pages 1-47, 2009.
PDF Abstract BibTex

Do Automatic Annotation Techniques Have Any Impact on Supervised Complex Question Answering?
Yllias Chali*, Sadid Hasan*, and Shafiq Joty*. In Proceedings of the ACL-IJCNLP 2009 Conference (ACL'09) , pages 329-332, 2009.
PDF Abstract BibTex Slides
Yllias Chali*, Sadid Hasan*, and Shafiq Joty*. In Proceedings of the ACL-IJCNLP 2009 Conference (ACL'09) , pages 329-332, 2009.
PDF Abstract BibTex Slides

A SVM-Based Ensemble Approach to Multi-Document Summarization
Yllias Chali*, Sadid Hasan*, and Shafiq Joty*. In Proceedings of the 22Nd Canadian Conference on Artificial Intelligence: Advances in Artificial Intelligence (Canadian AI '09) , pages 199-202, 2009.
PDF Abstract BibTex Slides
Yllias Chali*, Sadid Hasan*, and Shafiq Joty*. In Proceedings of the 22Nd Canadian Conference on Artificial Intelligence: Advances in Artificial Intelligence (Canadian AI '09) , pages 199-202, 2009.
PDF Abstract BibTex Slides

Finding Topics in Emails: Is LDA enough?
Shafiq Joty, Giuseppe Carenini, Gabriel Murray, and Raymond Ng. In NIPS-2009 workshop on applications for topic models: text and beyond 2009.
PDF Abstract BibTex Slides
Shafiq Joty, Giuseppe Carenini, Gabriel Murray, and Raymond Ng. In NIPS-2009 workshop on applications for topic models: text and beyond 2009.
PDF Abstract BibTex Slides
2008
Exploiting Syntactic and Shallow Semantic Kernels to Improve Random Walks for Complex Question Answering
Yllias Chali*, and Shafiq Joty*. In 20th IEEE International Conference on Tools with Artificial Intelligence (ICTAI'08) , pages 123-130, 2008.
PDF Abstract BibTex Slides
Yllias Chali*, and Shafiq Joty*. In 20th IEEE International Conference on Tools with Artificial Intelligence (ICTAI'08) , pages 123-130, 2008.
PDF Abstract BibTex Slides
Answering Complex Questions Using Query-Focused Summarization Technique
Yllias Chali*, and Shafiq Joty*. In 20th IEEE International Conference on Tools with Artificial Intelligence (ICTAI'08) , pages 123-130, 2008.
PDF Abstract BibTex Slides
Yllias Chali*, and Shafiq Joty*. In 20th IEEE International Conference on Tools with Artificial Intelligence (ICTAI'08) , pages 123-130, 2008.
PDF Abstract BibTex Slides

Unsupervised Approach for Selecting Sentences in Query-based Summarization.
Yllias Chali*, and Shafiq Joty*. In Proceedings of the Twenty-First International FLAIRS Conference (FLAIRS'08) , pages 47-52, 2008.
PDF Abstract BibTex Slides
Yllias Chali*, and Shafiq Joty*. In Proceedings of the Twenty-First International FLAIRS Conference (FLAIRS'08) , pages 47-52, 2008.
PDF Abstract BibTex Slides

The University of British Columbia at TAC 2008
Gabriel Murray, Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In Proceedings of the Text Analysis Conference (TAC'08) , pages 1-7, 2008.
PDF Abstract BibTex Slides
Gabriel Murray, Shafiq Joty, Giuseppe Carenini, and Raymond Ng. In Proceedings of the Text Analysis Conference (TAC'08) , pages 1-7, 2008.
PDF Abstract BibTex Slides
UofL at TAC 2008 Update Summarization and Question Answering
Yllias* Chali, Shafiq Joty*, and Sadid Hasan*. In Proceedings of the Text Analysis Conference (TAC'08) , pages 1-7, 2008.
PDF Abstract BibTex Slides
Yllias* Chali, Shafiq Joty*, and Sadid Hasan*. In Proceedings of the Text Analysis Conference (TAC'08) , pages 1-7, 2008.
PDF Abstract BibTex Slides
Improving the Performance of the Random Walk Model for Answering Complex Questions
Yllias Chali*, and Shafiq Joty*. In Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics (ACL'08) , pages 9-12, 2008.
PDF Abstract BibTex Slides
Yllias Chali*, and Shafiq Joty*. In Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics (ACL'08) , pages 9-12, 2008.
PDF Abstract BibTex Slides
Selecting Sentences for Answering Complex Questions
Yllias Chali*, and Shafiq Joty*. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP'08) , pages 304-313, 2008.
PDF Abstract BibTex Slides
Yllias Chali*, and Shafiq Joty*. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP'08) , pages 304-313, 2008.
PDF Abstract BibTex Slides
2007
University of Lethbridge's participation in DUC-2007 main task
Yllias Chali*, and Shafiq Joty*. In Proceedings of the Document Understanding Conference (DUC'07) , pages xx-xx, 2007.
PDF Abstract BibTex Slides
Yllias Chali*, and Shafiq Joty*. In Proceedings of the Document Understanding Conference (DUC'07) , pages xx-xx, 2007.
PDF Abstract BibTex Slides
University of Lethbridge's Participation in TREC-2007 QA Track
Yllias Chali*, and Shafiq Joty*. In Proceedings of the sixteenth Text Retrieval Conference (TREC'07) , pages xx-xx, 2007.
PDF BibTex Slides
Yllias Chali*, and Shafiq Joty*. In Proceedings of the sixteenth Text Retrieval Conference (TREC'07) , pages xx-xx, 2007.
PDF BibTex Slides
Word Sense Disambiguation Using Lexical Cohesion
Yllias Chali*, and Shafiq Joty*. In Proceedings of the 4th International Workshop on Semantic Evaluations (SemEval'07) , pages 476-479, 2007.
PDF Abstract BibTex Slides
Yllias Chali*, and Shafiq Joty*. In Proceedings of the 4th International Workshop on Semantic Evaluations (SemEval'07) , pages 476-479, 2007.
PDF Abstract BibTex Slides
Theses
2008
2013