
Unsupervised Summarization Re-ranking
Mathieu Ravaut, Shafiq Joty, and Nancy Chen
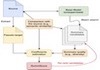
With the rise of task-specific pre-training objectives, abstractive summarization models like PEGASUS offer appealing zero-shot performance on downstream summarization tasks. However, the performance of such unsupervised models still lags significantly behind their supervised counterparts. Similarly to the supervised setup, we notice a very high variance in quality among summary candidates from these models whereas only one candidate is kept as the summary output. In this paper, we propose to re-rank summary candidates in an unsupervised manner, aiming to close the performance gap between unsupervised and supervised models. Our approach improves the pre-trained unsupervised PEGASUS by 4.37% to 7.27% relative mean ROUGE across four widely-adopted summarization benchmarks, and achieves relative gains of 7.51% (up to 23.73% from XSum to WikiHow) averaged over 30 transfer setups.
Unsupervised Summarization Re-ranking
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. In Findings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23 Findings) 2023.
PDF Abstract BibTex Slides
Mathieu Ravaut, Shafiq Joty, and Nancy Chen. In Findings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23 Findings) 2023.
PDF Abstract BibTex Slides