
Explaining Language Model Predictions with High-Impact Concepts
Ruochen Zhao, Shafiq Joty, Yongjie Wang, and Tan Wang
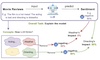
To encourage fairness and transparency, there exists an urgent demand for deriving reliable explanations for large language models (LLMs). One promising solution is concept-based explanations, i.e., human-understandable concepts from internal representations. However, due to the compositional nature of languages, current methods mostly discover correlational explanations instead of causal features. Therefore, we propose a novel framework to provide impact-aware explanations for users to understand the LLM's behavior, which are robust to feature changes and influential to the model's predictions. Specifically, we extract predictive high-level features (concepts) from the model's hidden layer activations. Then, we innovatively optimize for features whose existence causes the output predictions to change substantially. Extensive experiments on real and synthetic tasks demonstrate that our method achieves superior results on predictive impact, explainability, and faithfulness compared to the baselines, especially for LLMs.
Explaining Language Model Predictions with High-Impact Concepts
Ruochen Zhao, Shafiq Joty, Yongjie Wang, and Tan Wang. In Findings of ACL (EACL-24) 2024.
PDF Abstract BibTex Slides
Ruochen Zhao, Shafiq Joty, Yongjie Wang, and Tan Wang. In Findings of ACL (EACL-24) 2024.
PDF Abstract BibTex Slides