
Regularized and Retrofitted models for Learning Sentence Representation with Context
Tanay Saha, Shafiq Joty, Naeemul Hassan, and Mohammad Hasan
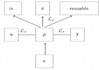
Vector representation of sentences is important for many text processing tasks that involve classifying, clustering, or ranking sentences. For solving these tasks, bag-of-word based representation has been used for a long time. In recent years, distributed representation of sentences learned by neural models from unlabeled data has been shown to outperform traditional bag-of-words representations. However, most existing methods belonging to the neural models consider only the content of a sentence, and disregard its relations with other sentences in the context. In this paper, we first characterize two types of contexts depending on their scope and utility. We then propose two approaches to incorporate contextual information into content-based models. We evaluate our sentence representation models in a setup, where context is available to infer sentence vectors. Experimental results demonstrate that our proposed models outshine existing models on three fundamental tasks, such as, classifying, clustering, and ranking sentences.
Regularized and Retrofitted models for Learning Sentence Representation with Context
Tanay Saha, Shafiq Joty, Naeemul Hassan, and Mohammad Hasan. In Proceedings of the 26th ACM International Conference on Information and Knowledge Management (CIKM'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides
Tanay Saha, Shafiq Joty, Naeemul Hassan, and Mohammad Hasan. In Proceedings of the 26th ACM International Conference on Information and Knowledge Management (CIKM'17) , pages xx-xx, 2017.
PDF Abstract BibTex Slides