
Unpaired Image Captioning via Scene Graph Alignments
Jiuxiang Gu, Shafiq Joty, Jianfei Cai, Handong Zhao, Xu Yang, and Gang Wang
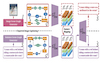
Deep neural networks have achieved great success on the image captioning task. However, most of the existing models depend heavily on paired image-sentence datasets, which are very expensive to acquire in most real-world scenarios. In this paper, we propose a scene graph based approach for unpaired image captioning. Our method merely requires an image set, a sentence corpus, an image scene graph generator, and a sentence scene graph generator. The sentence corpus is used to teach the decoder how to generate meaningful sentences from a scene graph. To further encourage the generated captions to be semantically consistent with the image, we employ adversarial learning to align the visual scene graph to the textual scene graph. Experimental results show that our proposed model can generate quite promising results without using any image-caption training pairs, outperforming existing methods by a wide margin.
Unpaired Image Captioning via Scene Graph Alignments
Jiuxiang Gu, Shafiq Joty, Jianfei Cai, Handong Zhao, Xu Yang, and Gang Wang. In Proceedings of the International Conference on Computer Vision (ICCV'19) , pages 10323-10332, 2019.
PDF Abstract BibTex Slides
Jiuxiang Gu, Shafiq Joty, Jianfei Cai, Handong Zhao, Xu Yang, and Gang Wang. In Proceedings of the International Conference on Computer Vision (ICCV'19) , pages 10323-10332, 2019.
PDF Abstract BibTex Slides