
Unsupervised Cross-lingual Image Captioning
Jiahui Gao, Yi Zhou, Philip Yu, Shafiq Joty, and Jiuxiang Gu
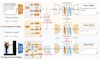
Research in image captioning has mostly focused on English because of the availability of image-caption paired datasets in this language. However, building vision-language systems only for English deprives a large part of the world population of AI technologies' benefit. On the other hand, creating image-caption paired datasets for every target language is expensive. In this work, we present a novel unsupervised cross-lingual method to generate image captions in a target language without using any image-caption corpus in the source or target languages. Our method relies on (i) a cross-lingual scene graph to sentence translation process, which learns to decode sentences in the target language from a cross-lingual encoding space of scene graphs using a sentence parallel (bitext) corpus, and (ii) an unsupervised cross-modal feature mapping which seeks to map an encoded scene graph features from image modality to language modality. We verify the effectiveness of our proposed method on the Chinese image caption generation task. The comparisons against several existing methods demonstrate the effectiveness of our approach.
Unsupervised Cross-lingual Image Captioning
Jiahui Gao, Yi Zhou, Philip Yu, Shafiq Joty, and Jiuxiang Gu. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI'22) 2022.
PDF Abstract BibTex Slides
Jiahui Gao, Yi Zhou, Philip Yu, Shafiq Joty, and Jiuxiang Gu. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI'22) 2022.
PDF Abstract BibTex Slides