
Efficiently Aligned Cross-Lingual Transfer Learning for Conversational Tasks using Prompt-Tuning
Lifu Tu, Jin Qu, Semih Yavuz, Shafiq Joty, Wenhao Liu, Caiming Xiong, and Yingbo Zhou
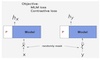
Cross-lingual transfer of language models trained on high-resource languages like English has been widely studied for many NLP tasks, but focus on conversational tasks has been rather limited. This is partly due to the high cost of obtaining non-English conversational data, which results in limited coverage. In this work, we introduce for cross-lingual alignment pretraining, a parallel and large-scale multilingual conversation dataset that we created by translating the English-only Schema-Guided Dialogue (SGD) dataset (Rastogi et al., 2020) into 105 other languages. XSGD contains about 330k utterances per language. To facilitate aligned cross-lingual representations, we develop an efficient prompt-tuning-based method for learning alignment prompts. We also investigate two different classifiers: NLI-based and vanilla classifiers, and test cross-lingual capability enabled by the aligned prompts. We evaluate our model's cross-lingual generalization capabilities on two conversation tasks: slot-filling and intent classification. Our results demonstrate strong and efficient modeling ability of NLI-based classifiers and the large cross-lingual transfer improvements achieved by our aligned prompts, particularly in few-shot settings. We also conduct studies on large language models (LLMs) such as text-davinci-003 and ChatGPT in both zero- and few-shot settings. While LLMs exhibit impressive performance in English, their cross-lingual capabilities in other languages, particularly low-resource ones, are limited.
Efficiently Aligned Cross-Lingual Transfer Learning for Conversational Tasks using Prompt-Tuning
Lifu Tu, Jin Qu, Semih Yavuz, Shafiq Joty, Wenhao Liu, Caiming Xiong, and Yingbo Zhou. In In Findings of ACL (EACL-24) 2024.
PDF Abstract BibTex Slides
Lifu Tu, Jin Qu, Semih Yavuz, Shafiq Joty, Wenhao Liu, Caiming Xiong, and Yingbo Zhou. In In Findings of ACL (EACL-24) 2024.
PDF Abstract BibTex Slides