
Finding It at Another Side: A Viewpoint-Adapted Matching Encoder for Change Captioning
Xiangxi Shi, Xu Yang, Jiuxiang Gu, Shafiq Joty, and Jianfei Cai
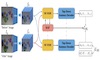
Change Captioning is a task that aims to describe the difference between images with natural language. Most existing methods treat this problem as a difference judgment without the existence of distractors such as viewpoint changes. However, in practice, viewpoint changes happen often and can overwhelm the real difference to be described. In this paper, we propose a novel visual encoder to explicitly distinguish viewpoint changes from real changes in the change captioning task. Moreover, we further simulate the attention preference of humans and propose a novel reinforcement learning process to fine-tune the attention directly with the language evaluation rewards. Extensive experimental results show that our method outperforms the state-of-the-art approaches by a large margin in both Spot-the-Diff and CLEVR-Change datasets.
Finding It at Another Side: A Viewpoint-Adapted Matching Encoder for Change Captioning
Xiangxi Shi, Xu Yang, Jiuxiang Gu, Shafiq Joty, and Jianfei Cai. In European Conference on Computer Vision (ECCV'20) 2020.
PDF Abstract BibTex Slides
Xiangxi Shi, Xu Yang, Jiuxiang Gu, Shafiq Joty, and Jianfei Cai. In European Conference on Computer Vision (ECCV'20) 2020.
PDF Abstract BibTex Slides