
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Junnan Li, Ramprasaath R., Akhilesh Deepak, Shafiq Joty, Caiming Xiong, and Steven Hoi
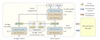
Large-scale vision and language representation learning has shown promising improvements on various vision-language tasks. Most existing methods employ a transformer-based multimodal encoder to jointly model visual tokens (region-based image features) and word tokens. Because the visual tokens and word tokens are unaligned, it is challenging for the multimodal encoder to learn image-text interactions. In this paper, we introduce a contrastive loss to ALign the image and text representations BEfore Fusing (ALBEF) them through cross-modal attention, which enables more grounded vision and language representation learning. Unlike most existing methods, our method does not require bounding box annotations nor high-resolution images. In order to improve learning from noisy web data, we propose momentum distillation, a self-training method which learns from pseudo-targets produced by a momentum model. We provide a theoretical analysis of ALBEF from a mutual information maximization perspective, showing that different training tasks can be interpreted as different ways to generate views for an image-text pair. ALBEF achieves state-of-the-art performance on multiple downstream vision-language tasks. On image-text retrieval, ALBEF outperforms methods that are pre-trained on orders of magnitude larger datasets. On VQA and NLVR2, ALBEF achieves absolute improvements of 2.37\% and 3.84\% compared to the state-of-the-art, while enjoying faster inference speed. Code and pre-trained models are available at .
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Junnan Li, Ramprasaath R., Akhilesh Deepak, Shafiq Joty, Caiming Xiong, and Steven Hoi. In 2021 Conference on Neural Information Processing Systems (NeurIPS'21 (spotlight ~3%)) 2021.
PDF Abstract BibTex Slides
Junnan Li, Ramprasaath R., Akhilesh Deepak, Shafiq Joty, Caiming Xiong, and Steven Hoi. In 2021 Conference on Neural Information Processing Systems (NeurIPS'21 (spotlight ~3%)) 2021.
PDF Abstract BibTex Slides