
Speech Transformer with Speaker Aware Persistent Memory
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma
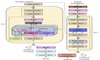
End-to-end models have been introduced into automatic speech recognition (ASR) successfully and achieved superior performance compared with conventional hybrid systems, especially with the newly proposed transformer model. However, speaker mismatch between training and test data remains a problem, and speaker adaptation for transformer model can be further improved. In this paper, we propose to conduct speaker aware training for ASR in transformer model. Specifically, we propose to embed speaker knowledge through a persistent memory model into speech transformer encoder at utterance level. The speaker information is represented by a number of static speaker i-vectors, which is concatenated to speech utterance at each encoder self-attention layer. Persistent memory is thus formed by carrying speaker information through the depth of encoder. The speaker knowledge is captured from self-attention between speech and persistent memory vector in encoder. Experiment results on LibriSpeech, Switchboard and AISHELL-1 ASR task show that our proposed model brings relative 4.7%-12.5% word error rate (WER) reductions, and achieves superior results compared with other models with the same objective. Furthermore, our model brings relative 2.1%-8.3% WER reductions compared with the first persistent memory model used in ASR.
Speech Transformer with Speaker Aware Persistent Memory
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In 21st Annual Conference of the International Speech Communication Association (Interspeech'20) , pages 1261 - 1265, 2020.
PDF Abstract BibTex Slides
Yingzhu Zhao, Chongjia Ni, Cheung-Chi LEUNG, Shafiq Joty, Eng Siong, and Bin Ma. In 21st Annual Conference of the International Speech Communication Association (Interspeech'20) , pages 1261 - 1265, 2020.
PDF Abstract BibTex Slides