
Towards Robust Low-Resource Fine-Tuning with Multi-View Compressed Representations
Linlin Liu, Xingxuan Li, Megh Thakkar, Xin Li, Shafiq Joty, Luo Si, and Lidong Bing
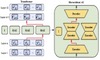
Due to the huge amount of parameters, fine-tuning of pretrained language models (PLMs) is prone to overfitting in the low-resource scenarios. In this work, we present a novel method that operates on the hidden representations of a PLM to reduce overfitting. During fine-tuning, our method inserts random autoencoders between the hidden layers of a PLM, which transform activations from the previous layers into a multi-view compressed representation before feeding it into the upper layers. The autoencoders are plugged out after fine-tuning, so our method does not add extra parameters or increase computation cost during inference. Our method demonstrates promising performance improvement across a wide range of sequence- and token-level low-resource NLP tasks. We will make our source code publicly available for research purposes.
Towards Robust Low-Resource Fine-Tuning with Multi-View Compressed Representations
Linlin Liu, Xingxuan Li, Megh Thakkar, Xin Li, Shafiq Joty, Luo Si, and Lidong Bing. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides
Linlin Liu, Xingxuan Li, Megh Thakkar, Xin Li, Shafiq Joty, Luo Si, and Lidong Bing. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL'23) 2023.
PDF Abstract BibTex Slides