
LNMap: Departures from Isomorphic Assumption in Bilingual Lexicon Induction Through Non-Linear Mapping in Latent Space
Tasnim Mohiuddin, M Saiful, and Shafiq Joty
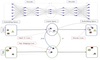
Most of the successful and predominant methods for bilingual lexicon induction (BLI) are mapping-based, where a linear mapping function is learned with the assumption that the word embedding spaces of different languages exhibit similar geometric structures (i.e., approximately isomorphic). However, several recent studies have criticized this simplified assumption showing that it does not hold in general even for closely related languages. In this work, we propose a novel semi-supervised method to learn cross-lingual word embeddings for BLI. Our model is independent of the isomorphic assumption and uses nonlinear mapping in the latent space of two independently trained auto-encoders. Through extensive experiments on fifteen (15) different language pairs (in both directions) comprising resource-rich and low-resource languages from two different datasets, we demonstrate that our method outperforms existing models by a good margin. Ablation studies show the importance of different model components and the necessity of non-linear mapping.
LNMap: Departures from Isomorphic Assumption in Bilingual Lexicon Induction Through Non-Linear Mapping in Latent Space
Tasnim Mohiuddin, M Saiful, and Shafiq Joty. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 2712–-2723, 2020.
PDF Abstract BibTex Slides
Tasnim Mohiuddin, M Saiful, and Shafiq Joty. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP'20) , pages 2712–-2723, 2020.
PDF Abstract BibTex Slides